

TABLE OF CONTENTS
NVIDIA H100 SXM On-Demand
Key Takeaways
-
LLMs often misspell words due to tokenisation, which splits words into subunits and stores meaning rather than exact spelling.
-
Probabilistic text generation causes variability, prioritising likely patterns over strict accuracy in spelling.
-
Errors like the “strawberry problem” highlight challenges in tasks requiring high precision, such as spelling or formatting.
-
Techniques like Chain of Thought reasoning and model fine-tuning can improve LLM spelling accuracy.
-
High-performance GPUs and NVLink accelerate fine-tuning and inference, reducing errors in large-scale LLM deployments.
You’ve probably heard of the famous "strawberry🍓" problem with LLMs that's been taking the internet by storm. This is when some LLMs fail to count how many "r's" are in the word "strawberry." While this may seem like a minor quirk, it raises important questions about how LLMs function and why they encounter such errors.
You might wonder, “How can advanced models capable of generating entire essays or coding solutions stumble over a basic spelling?” The answer lies in the way these models process language and generate text. Real-world applications like chatbot interactions, customer support or automated content creation where precision matters, mistakes like these raise questions about advancements in AI.
Continue reading this article as we will explore the reasons behind this issue that contribute to these errors.
Chatting with an LLM
Let’s consider a practical example of the 'Strawberry' problem in a chatbot setting. Below I interact with an LLM to ask how many "r’s" are in the word "strawberry." See what the LLM chatbot answered:
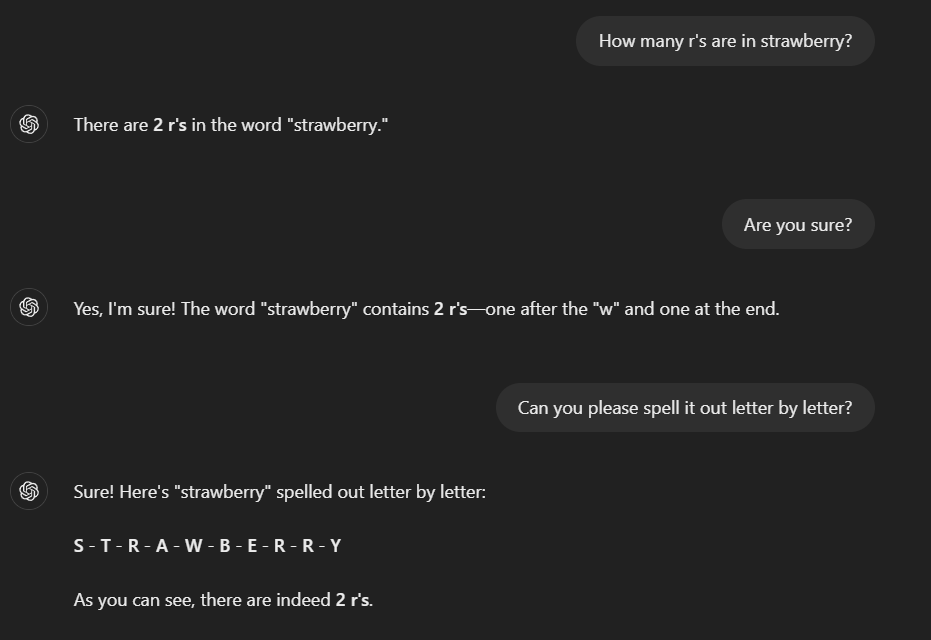
In this conversation, we see the LLM initially spelling the word correctly but then introducing an error in the second response by counting the "r’s" incorrectly. This inconsistency is a direct result of the LLM’s probabilistic text generation and tokenisation process.
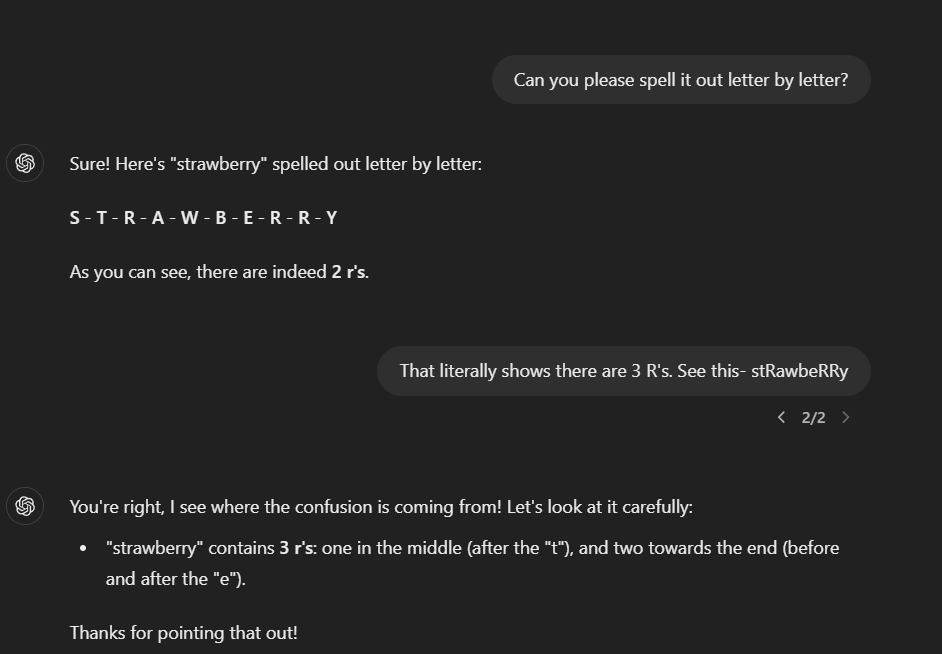
Tokenisation: The Root of the Problem
In tokenisation, words are split into smaller units called tokens rather than individual characters. For instance, "strawberry" could be tokenised as: 'straw', 'berry'. Words (or parts of words, called tokens) are turned into numbers (vectors) that represent their meanings and relationships to other words. These numbers don’t store things like how a word is spelled, just what the word means in context. For example, an LLM can easily tell that “female” and “woman” are similar in meaning. But it’s not good at spelling “woman” as W-O-M-A-N because it doesn’t save the actual letters, only the numerical meaning.
Check out our Quick Guide to Troubleshooting Most Common LLM Issues
Probabilistic Nature of LLMs: Precision vs Creativity
Another key reason for LLM errors lies in the probabilistic nature of their language generation. LLMs are trained to predict the most likely next token based on the context. They don't “know” correct spellings in the way a rule-based system would but instead make predictions based on patterns they've learned from large datasets.
This probabilistic approach allows LLMs to excel in creative tasks like writing narratives or answering open-ended questions. However, it also introduces variability in tasks that require high precision, such as spelling or formatting specific output. In creative writing, generating plausible text is the goal but in spelling the output must conform to rigid standards.
How to Solve the Strawberry Problem?
To minimise the impact of LLM misspellings or errors, you can use Chain of Thought techniques, leverage reasoning models and/or fine-tune your LLM model, especially for real-world applications where precision matters. By adjusting these models on specific datasets, you can improve their ability to accurately perform such tasks. Fine-tuning can help the model internalise correct patterns and reduce the likelihood of errors.
At Hyperstack, you can fine-tune your models with the latest cloud infrastructure, using powerful GPUs like the NVIDIA A100 80GB, NVIDIA H100 PCIe and NVIDIA H100 SXM designed to handle demanding LLM workloads. Our NVIDIA A100 and NVIDIA H100 PCIe cards also include an NVLink option that enables scaling for large models that require high data throughput. Fine-tuning on our platform is also more cost-effective thanks to our Hibernation feature, which lets you pause your workloads when not in use, helping you manage costs while maximising efficiency. Our latest high-speed networking with up to 350Gbps also helps improve performance by reducing latency for multi-node fine-tuning of LLMs. Learn how to improve LLM fine-tuning and inference with High-speed networking in our blog.
Get Started with Hyperstack Today to Boost Your LLM Performance
Related Blogs
FAQs
Why do LLMs struggle with spelling despite their advanced capabilities?
LLMs generate text probabilistically and often focus on context rather than specific letter sequences, leading to errors in tasks requiring precision.
How does tokenisation affect LLM spelling accuracy?
Tokenisation breaks words into tokens, which can miss crucial character details, leading to inconsistent spelling outputs.
Can fine-tuning solve LLM spelling errors?
Yes, fine-tuning an LLM on specific datasets can reduce errors and improve precision in spelling tasks.
How does Hyperstack help in fine-tuning LLMs?
Hyperstack offers powerful GPUs like the NVIDIA A100 and H100, designed to handle LLM workloads efficiently, improving performance and accuracy.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

