.png)
TABLE OF CONTENTS

Updated: 11 Feb 2025
NVIDIA H100 SXM On-Demand
Remember when implementing AI models was an expensive and inclusive approach? Those were the early days of AI adoption but thanks to the companies releasing their AI models as open source to help innovate and apply AI at scale. Unlike proprietary models that require costly licensing fees, open-source models offer a cost-effective solution with added advantages. These include improved security and data control, transparency into the model's architecture and training data. And the best part? You can customise and fine-tune the models to suit your specific needs.
List of Meta's New AI Research Models
Similarly, Meta's decision to make Llama 3 open source led to a new wave of innovation across the AI stack with developer tools, evaluation methods and optimising AI inference for performance and efficiency. But the good news is that Meta is doubling down on its commitment to open-source AI by releasing several models. Each model is developed to tackle unique challenges, from image generation to responsibility using the models. In this blog, we will explore Meta’s new AI models.
Also Read: Deploying and Using Llama 3.1-70B on Hyperstack
Chameleon
Meta's new AI model called Chameleon is a family of models that can combine text and images as input and output any combination of the two. Unlike traditional models, Chameleon uses tokenisation for both text and images. This creates a unified approach to encoding and decoding. This architecture simplifies the design, maintenance and scalability of the model.
While Meta has taken steps to develop these models responsibly, they also acknowledge the inherent risks associated with such powerful AI capabilities. As a result, Meta has chosen not to release the Chameleon image generation model at this time. Instead, they are sharing key components of the Chameleon 7B and 34B models under a research-only license, with the hope of encouraging the research community to design new detection and mitigation strategies that will enable responsible scaling of generative modelling research.
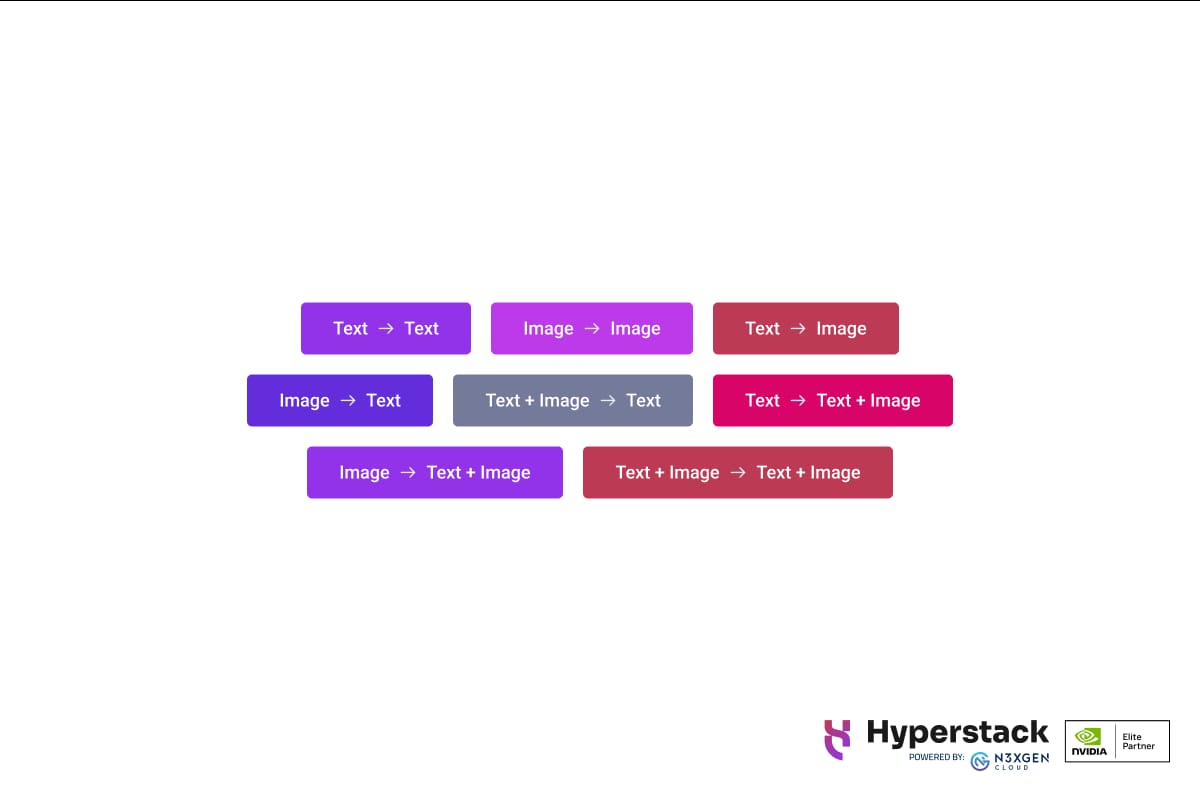
Image Source: Meta
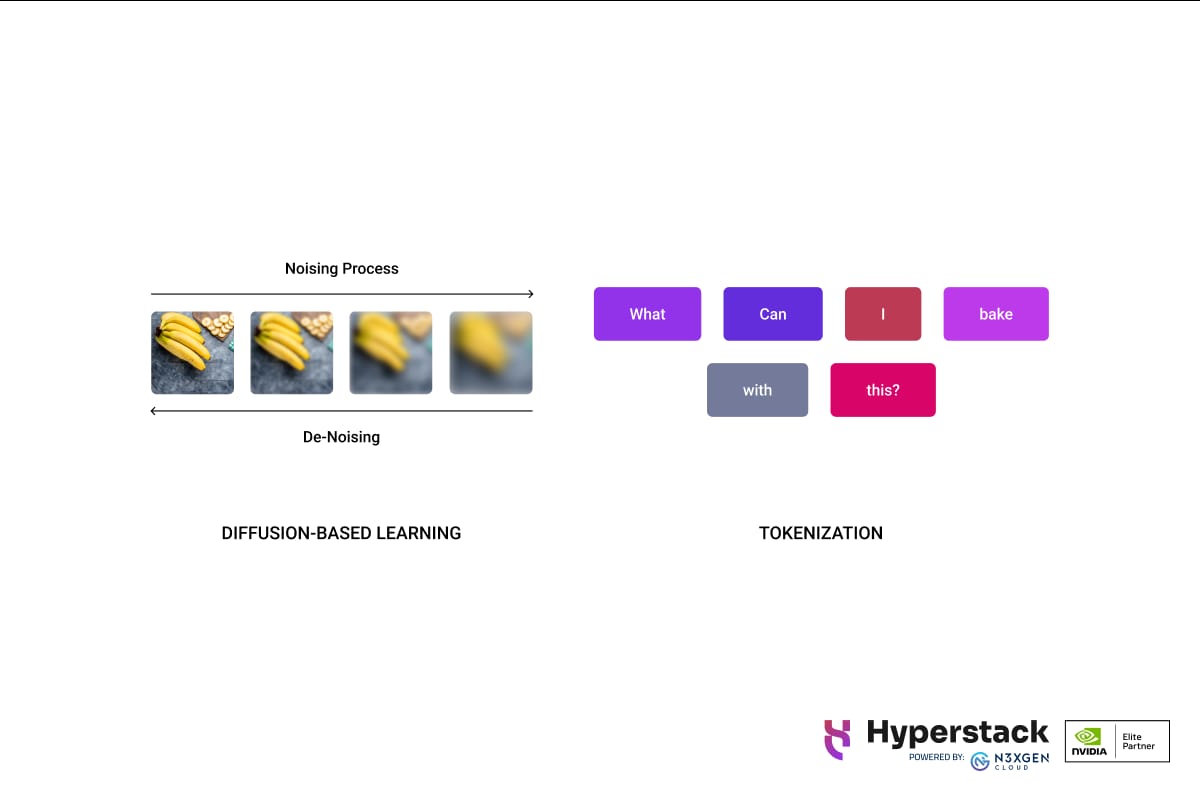
Image Source: Meta
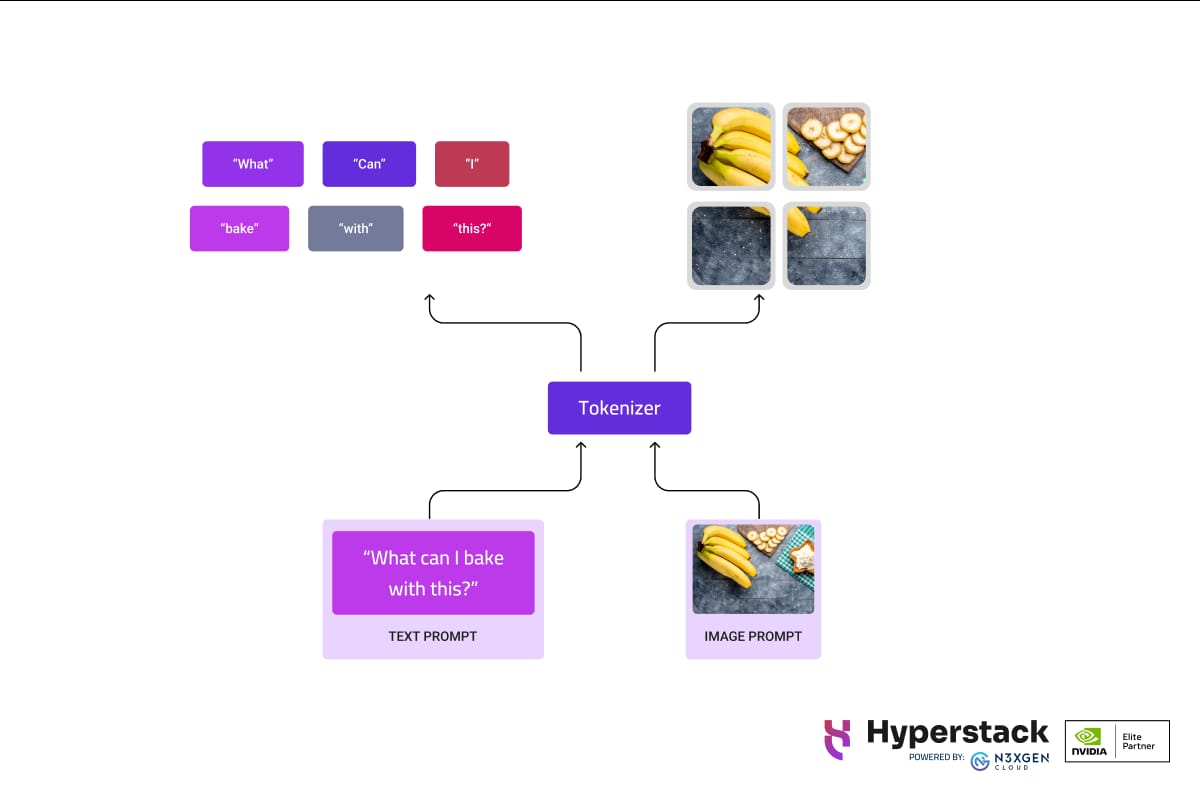
Image Source: Meta
Also Read: Phi-3: Microsoft's Latest Open AI Small Language Models
Multi-Token Prediction
Most modern large language models are trained to predict the next word, a simple but inefficient approach. Meta's new Multi-Token Prediction model challenges this by training language models to predict multiple future words simultaneously. Committing to responsible open science, Meta has released the pre-trained models for code completion but under a non-commercial/research-only license. This means that they can be used freely for academic and research purposes but not for commercial applications. However, with an emphasis on open science, this allows the research community to investigate the models independently.
Also Read: Exploring the Potential of Multimodal AI
JASCO
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation (JASCO) model is another model released by Meta. But hold on, it is not like the existing text-to-music models that primarily rely on text inputs, JASCO accepts various conditioning inputs, such as specific chords or beats for greater control over the generated music outputs. By applying information bottleneck layers and temporal blurring, JASCO can incorporate both symbolic and audio-based conditions. So you don’t have to worry about losing creative control over AI-powered music generation.
However, it is important to note that JASCO will be partially open source. The inference code for JASCO will be released under the MIT license as part of the AudioCraft repository. While the pre-trained model will be released under the CC-BY-NC license. The license allows others to use, share and modify the model, but only for non-commercial purposes.
Also Read: OpenAI Releases Latest AI Flagship Model GPT- 4o
AudioSeal
Almost every AI model is now being developed with a "safety-first" approach because companies realise the responsible use of AI. Meta has taken a proactive stance in this regard by releasing AudioSeal. Unlike traditional watermarking methods that rely on complex decoding algorithms, AudioSeal's localised detection approach allows for faster and more efficient detection. This makes it highly suitable for real-world applications of large AI models. This improves the detection speed by up to 485 times compared to previous methods. So you achieve state-of-the-art performance in audio watermarking in terms of robustness and imperceptibility. However, it is important to know that AudioSeal is being released under a commercial license.
Also Read: 5 Best Open Source Generative AI Models in 2024
Conclusion
In conclusion, Meta's latest models are a big leap forward in accelerating AI applications. These models offer advanced capabilities and performance. From image generation to text-to-music models, Meta has yet again proved its position as one of the top leaders in AI. You can download these models on Hugging Face and fine-tune/inference them using our Hyperstack GPUs for optimal performance:
- For inference tasks, we recommend using NVIDIA L40, NVIDIA A100 and NVIDIA H100 PCIe GPUs.
- For fine-tuning, we recommend using NVIDIA A100, H100 PCIe and NVIDIA H100 SXM GPUs for exceptional efficiency and speed.
Get started today to explore the potential of our high-end NVIDIA GPUs for AI Acceleration.
Similar Reads:
FAQs
How does Meta's Chameleon model differ from traditional models?
Chameleon uses a unified approach to encoding and decoding both text and images. This helps in simplifying the model's design and scalability.
What is the significance of Meta's Multi-Token Prediction model?
The Multi-Token Prediction model trains language models to predict multiple future words simultaneously, aiming for more efficient and capable language models.
What makes JASCO unique compared to existing text-to-music models?
JASCO accepts various conditioning inputs, such as specific chords or beats for greater control over the generated music outputs.
How does AudioSeal contribute to responsible AI development?
AudioSeal is an efficient audio watermarking method that improves detection speed and enables real-world applications of large AI models with state-of-the-art performance.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 7 Jan 2025
7 Jan 2025