

TABLE OF CONTENTS
NVIDIA A100 GPUs On-Demand

Llama 3.1 is the latest model in Meta's successful Llama series with enhanced performance, improved context understanding and better-nuanced language generation capabilities. One of the most significant improvements in Llama 3.1 size is the extended context length of 128K tokens, a massive increase from the Llama 3.18b context length. With approximately 70 billion parameters, Llama 3.1 can be easily deployed on high-end NVIDIA GPUs. Read this guide to learn how to deploy on Hyperstack along with Llama 3.1 requirements.
Why Deploy on Hyperstack?
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Llama 3.1-70B:
- Availability: Hyperstack provides access to the latest and most powerful GPU for Llama 3 such as the NVIDIA H100 on-demand, specifically designed to handle large language models.
- Ease of Deployment: With pre-configured environments and one-click deployments, setting up complex AI models becomes significantly simpler on our platform.
- Scalability: You can easily scale your resources up or down based on your computational needs.
- Cost-Effectiveness: You pay only for the resources you use with our cost-effective cloud GPU pricing.
- Integration Capabilities: Hyperstack provides easy integration with popular AI frameworks and tools.
Deployment Process
Now, let's walk through the step-by-step process of deploying Llama 3.1-70B on Hyperstack along with Llama 3,1 requirements.
Step 1: Accessing Hyperstack
- Go to the Hyperstack website and log in to your account.
- If you're new to Hyperstack, you'll need to create an account and set up your billing information. Check our documentation to get started with Hyperstack.
- Once logged in, you'll be greeted by the Hyperstack dashboard, which provides an overview of your resources and deployments.
Step 2: Deploying a New Virtual Machine
Initiate Deployment
- Look for the "Deploy New Virtual Machine" button on the dashboard.
- Click it to start the deployment process.
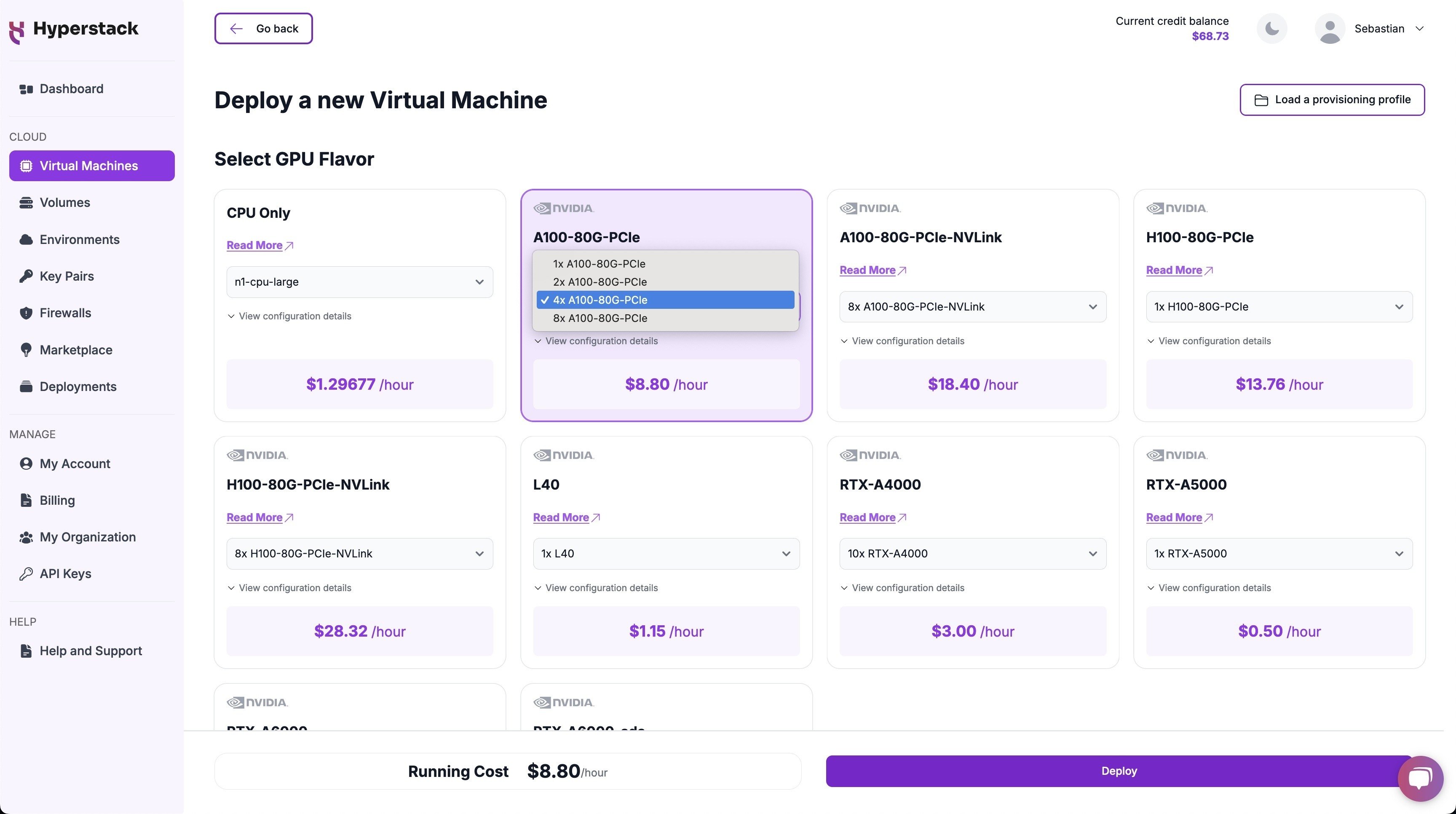
Select Hardware Configuration
- In the hardware options, choose the "4xA100-80G-PCIe" flavor.
- This configuration for Llama 3.1 70b GPU requirement, provides 4 NVIDIA A100 GPUs with 80GB memory each, connected via PCIe, offering exceptional performance for running Llama 3.1-70B.
- If you don't need this context length, you may consider using a 2xA100-80G-PCIe and then reducing the max model length by setting this command at the end of the Docker run command:
--max_model_length 4096
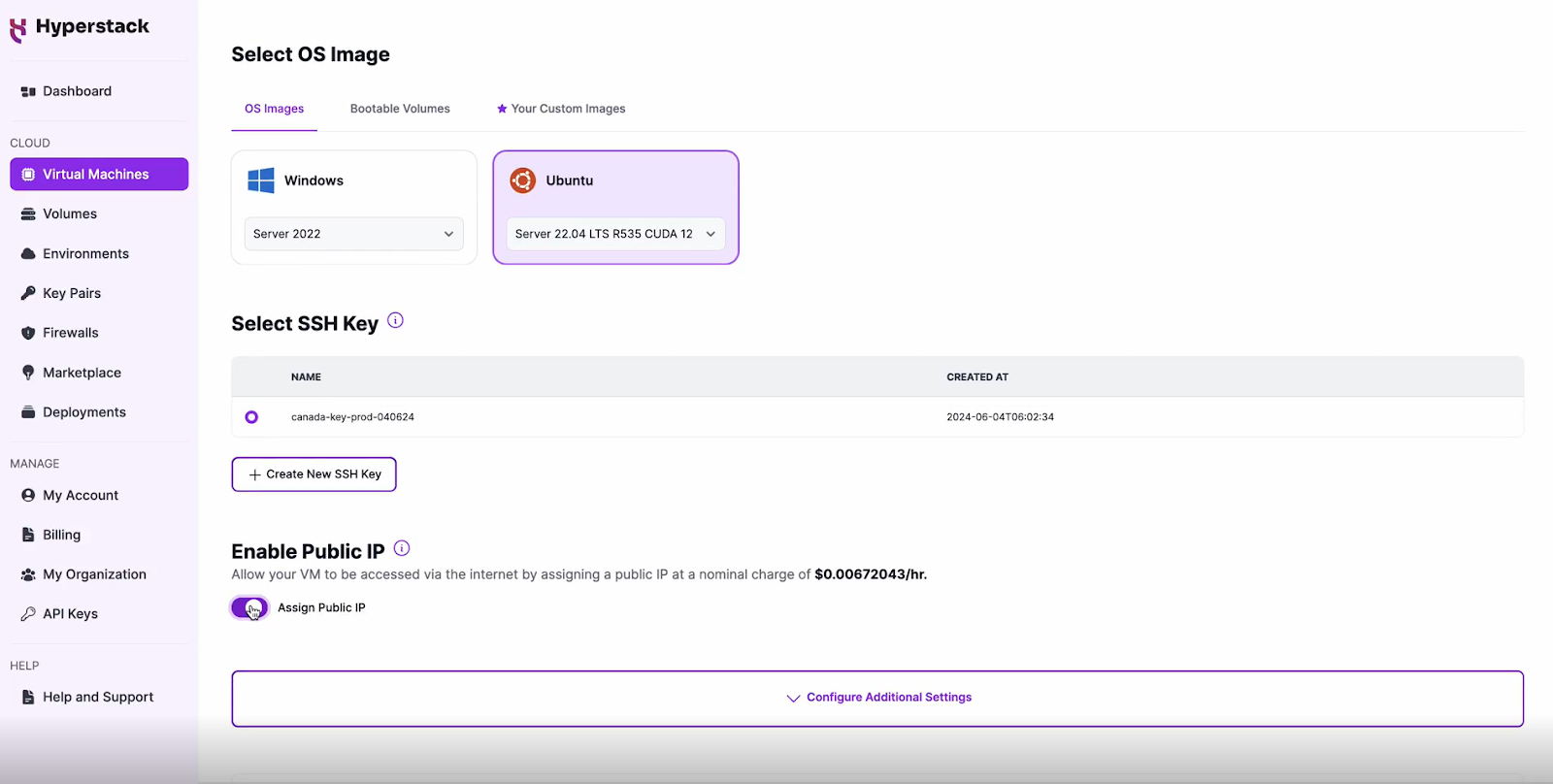
Choose the Operating System
- Select the "Server 22.04 LTS R535 CUDA 12.2".
- This image comes pre-installed with Ubuntu 22.04 LTS and NVIDIA drivers (R535) along with CUDA 12.2, providing an optimised environment for AI workloads.
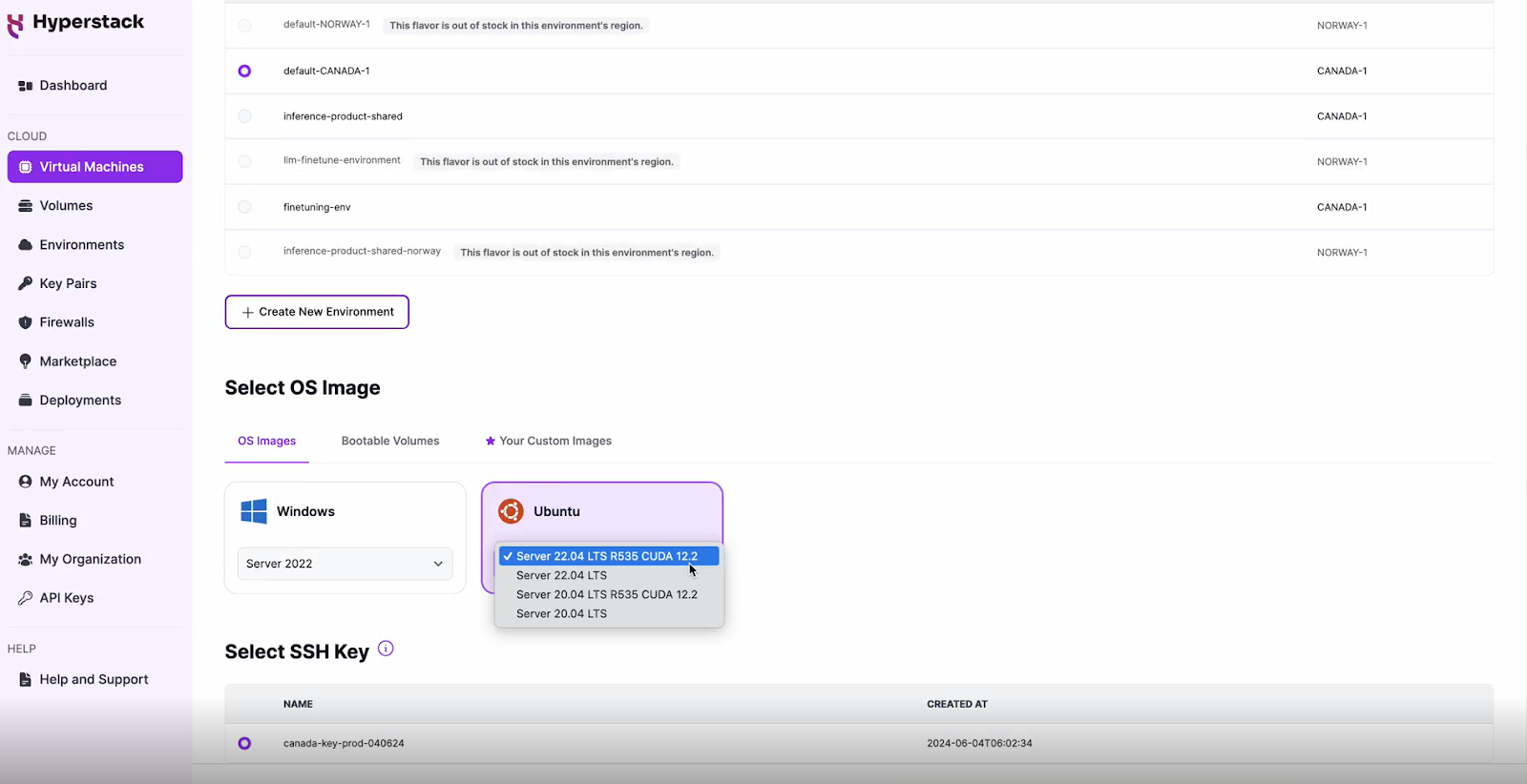
Select a keypair
- Select one of the keypairs in your account. Don't have a keypair yet? See our Getting Started tutorial for creating one.
Network Configuration
- Ensure you assign a Public IP to your Virtual machine.
- This allows you to access your VM from the internet, which is crucial for remote management and API access.
Enable SSH Access
- Make sure to enable an SSH connection.
- You'll need this to securely connect and manage your VM.
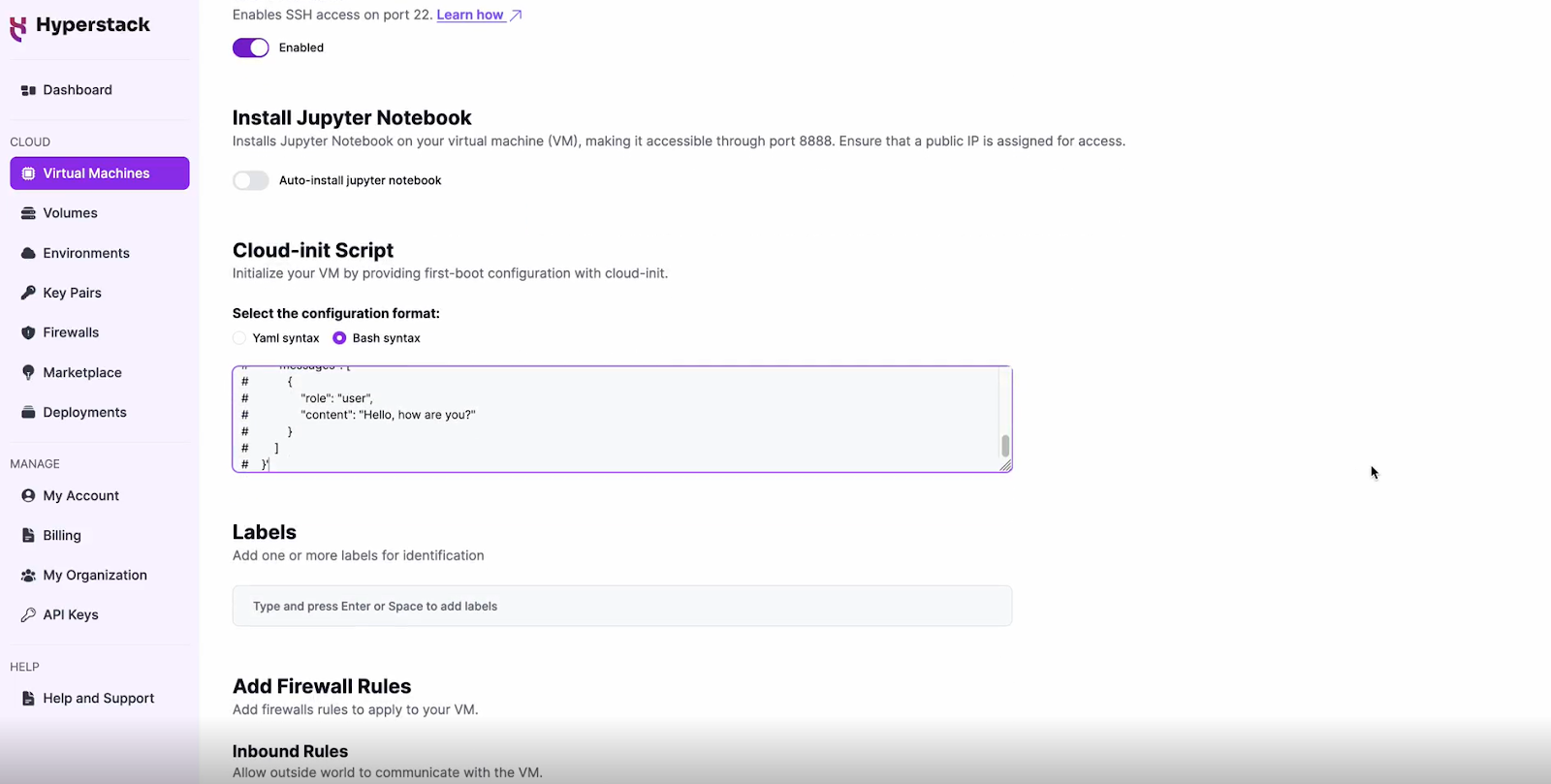
Configure Additional Settings
- Look for an "Additional Settings" or "Advanced Options" section.
- Here, you'll find a field for cloud-init scripts. This is where you'll paste the initialisation script. Click here to get the cloud-init script!
- Ensure the script is in bash syntax. This script will automate the setup of your Llama3.1-70B environment.
Please note: The above script deploys the NousResearch version of Llama3.1-70B. This allows you to get started with Llama-3.1-70B without a HuggingFace account and HuggingFace token. If you want to use the original model by meta, please have a look at the comments in the cloud-init script.
Review and Deploy
- Double-check all your settings.
- Click the "Deploy" button to launch your virtual machine.
Step 3: Initialisation and Setup
After deploying your VM, the cloud-init script will begin its work. This process typically takes about 7 minutes. During this time, the script performs several crucial tasks:
- Dependencies Installation: Installs all necessary libraries and tools required to run Llama3.1-70B.
- Model Download: Fetches the Llama3.1-70B model files from the specified repository.
- API Setup: Configures the vLLM engine and sets up an OpenAI-compatible API endpoint on port 8000.
While waiting, you can prepare your local environment for SSH access and familiarise yourself with the Hyperstack dashboard.
Step 4: Accessing Your VM
Once the initialisation is complete, you can access your VM:
Locate SSH Details
- In the Hyperstack dashboard, find your VM's details.
- Look for the public IP address, which you will need to connect to your VM with SSH.
Connect via SSH
- Open a terminal on your local machine.
- Use the command ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address] (e.g: ssh -i /users/username/downloads/keypair_hyperstack ubuntu@0.0.0.0.0)
- Replace username and ip_address with the details provided by Hyperstack.
Interacting with Llama 3.1-70B
To access and experiment with Meta's latest model, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Llama3.1-70B.
MODEL_NAME="NousResearch/Meta-Llama-3.1-70B-Instruct"
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "'$MODEL_NAME'",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}'
If the API is not working after ~10 minutes, please refer to our 'Troubleshooting Llama 3.1-70B' section below.
Troubleshooting Llama 3.1-70B
If you are having any issues, you might need to restart your machine before calling the API:
-
Run
sudo rebootinside your VM -
Wait 5-10 minutes for the VM to reboot
-
SSH into your VM
-
Wait ~3 minutes for the LLM API to boot up
-
Run the above API call again
If you are still having issues, try:
-
Run
docker psand find the container_id of your API container -
Run
docker logs [container_id]to see the logs of your container -
Use the logs to debug any issues
Step 5: Hibernating Your VM
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
- In the Hyperstack dashboard, locate your Virtual machine.
- Look for a "Hibernate" option.
- Click to hibernate the VM, which will stop billing for compute resources while preserving your setup.
To continue your work without repeating the setup process:
- Return to the Hyperstack dashboard and find your hibernated VM.
- Select the "Resume" or "Start" option.
- Wait a few moments for the VM to become active.
- Reconnect via SSH using the same credentials as before.
Explore our tutorials on Deploying and Using Flux.1 and Llama 3.1 70B on Hyperstack.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

