Llama 4 Maverick is a 17B active and 400B total parameters AI model developed by Meta as part of its Llama 4 series. It is a natively multimodal system capable of processing and integrating various data types, including text, images, video, and audio. Designed to outperform models like GPT-4o and Gemini 2.0, Llama 4 Maverick offers advanced capabilities in handling complex tasks across multiple modalities.
The features of Meta Llama 4 Maverick include:
Multimodal Capabilities: Processes and integrates text, images, video, and audio data. The native multimodal also supports 1M context length.
High Parameter Count: Utilises 17 billion active and 400B total parameters with a mixture of 128 experts.
Open-Weight Model: Shares pre-trained parameters while keeping training data and architecture proprietary.
Optimised Resource Usage: Employs a mixture of expert (MoE) architecture for efficient processing.
Reduced Bias: Shows improved balance and neutrality in responses to contentious topics.
Now, let's walk through the step-by-step process of deploying Llama 4 Maverick on Hyperstack.
Initiate Deployment
Select Hardware Configuration
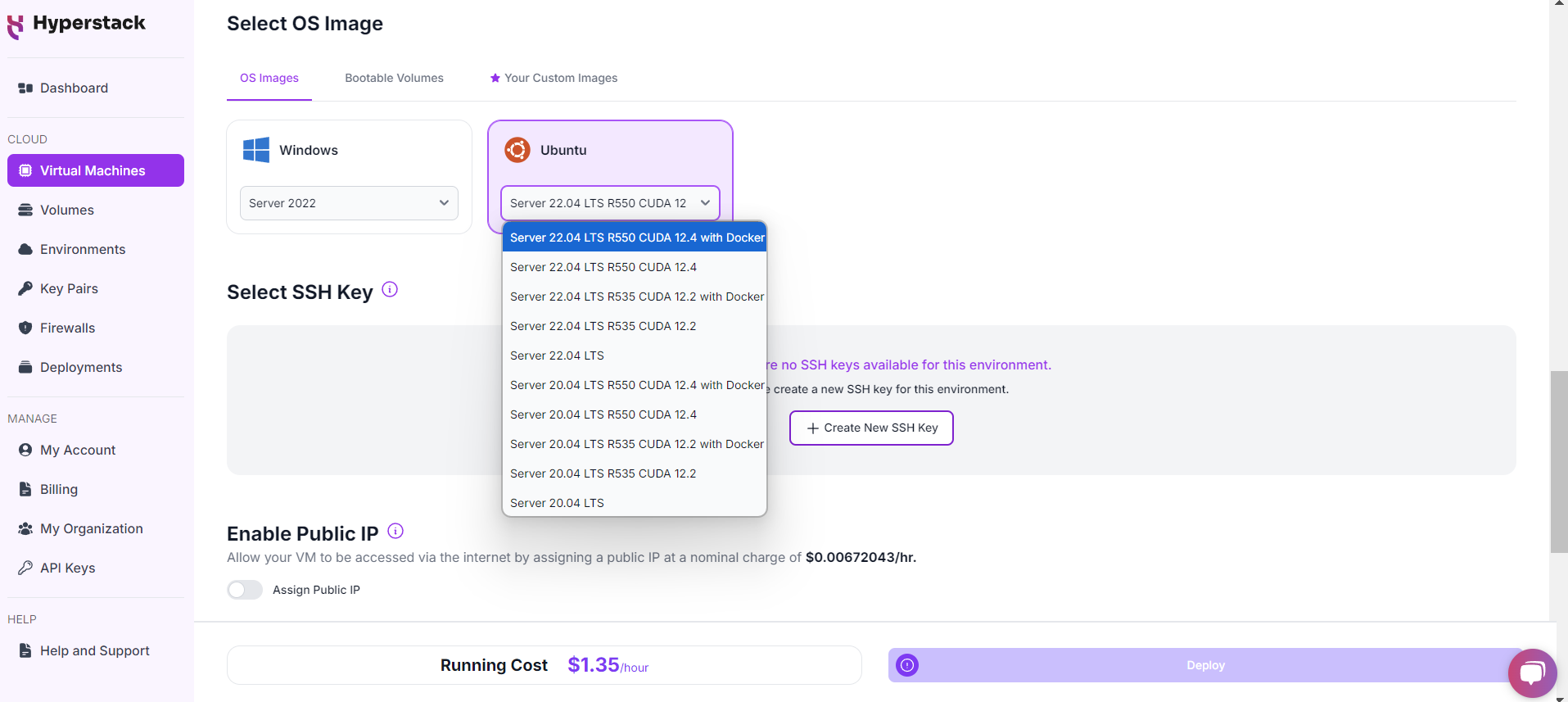
Choose the Operating System
Select a keypair
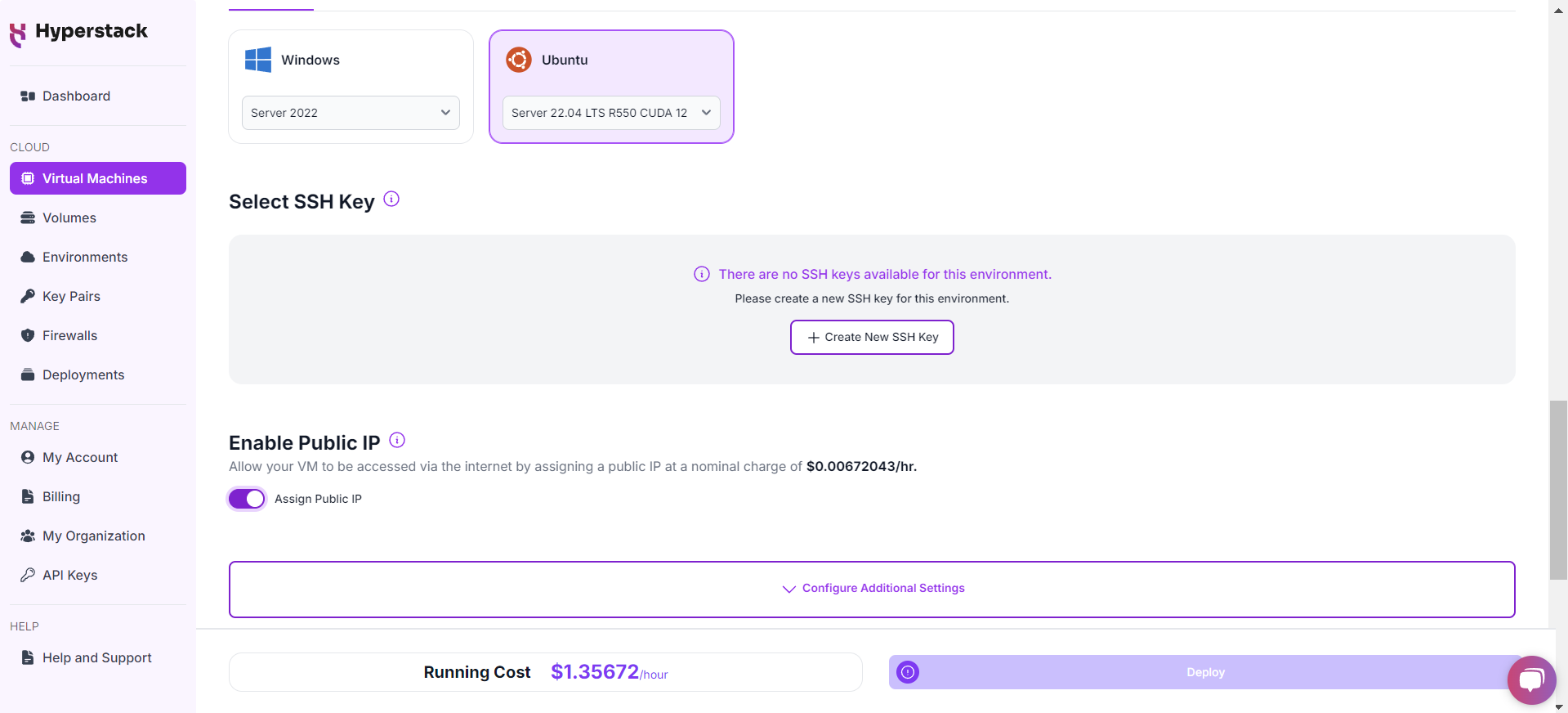
Network Configuration
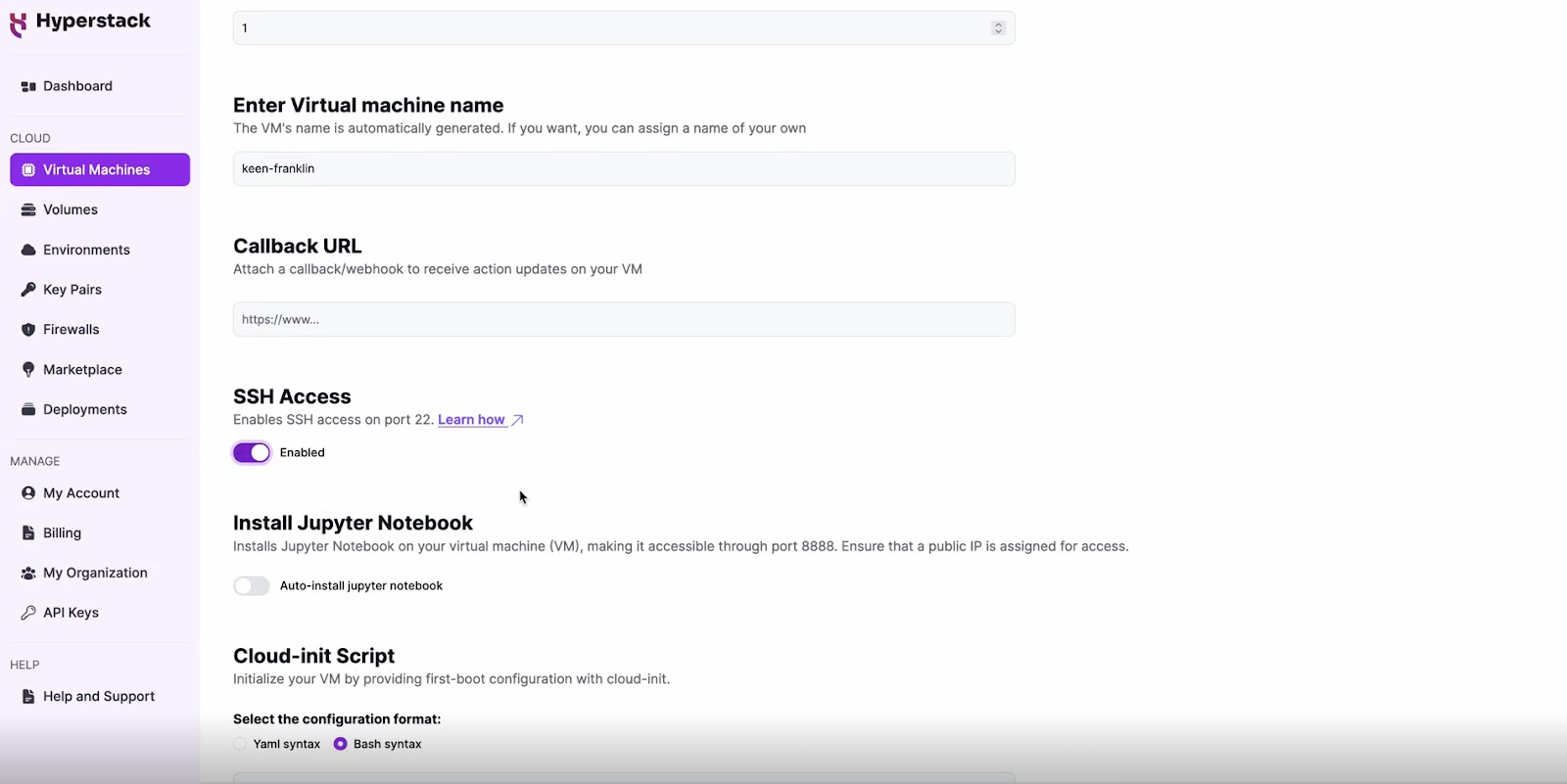
Enable SSH Access
Configure Additional Settings
To use the Llama 4 Maverick you need to:
Please note: this cloud-init script will only enable the API once for demo-ing purposes. For production environments, consider using containerization (e.g. Docker), secure connections, secret management, and monitoring for your API.
Review and Deploy
Please Note: This script will deploy the model with 430k context size. For the full context size (1M tokens) we suggest a multi-node setup which is out of scope for this tutorial.
After deploying your VM, the cloud-init script will begin its work. This process typically takes about 5-10 minutes. During this time, the script performs several crucial tasks:
While waiting, you can prepare your local environment for SSH access and familiarise yourself with the Hyperstack dashboard.
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
To access and experiment with Llama 4 Maverick, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Llama 4 Maverick:
MODEL_NAME="meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8"
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "'$MODEL_NAME'",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
]
}'If you are having any issues, please follow the following instructions:
SSH into your VM.
Check the cloud-init logs with the following command: cat /var/log/cloud-init-output.log
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Llama 4 Maverick:
New to Hyperstack? Log in to Get Started with Our Ultimate Cloud GPU Platform Today!
Llama 4 Maverick is a 17-billion active parameter AI model developed by Meta, featuring multimodal capabilities to process text, images, video and audio.
It offers enhanced multimodal processing, a higher parameter count, and improved performance in coding and reasoning tasks compared to earlier models.
Its multimodal capabilities make it suitable for applications requiring the integration of text, images, video, and audio, such as advanced conversational AI, content creation and data analysis.
Llama 4 Maverick outperforms GPT-4o and Gemini 2.0 Flash in various benchmarks and matches DeepSeek v3 in reasoning and coding with fewer parameters. It offers top performance-to-cost efficiency, scoring an ELO of 1417 on LMArena.
You can easily access the latest Llama 4 Maverick models on llama.com and Hugging Face.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}