Mistral AI’s Pixtral Large is a cutting-edge 123B multimodal model that excels in image and text understanding. With a 128K context window capable of fitting over 30 high-res images, it outperforms competitors on benchmarks like MathVista, DocVQA and VQAv2. Pixtral Large surpasses GPT-4 and Gemini-1.5 Pro in complex visual reasoning and real-world multimodal tasks. The model is available for both research and commercial use.
To get started, read our latest tutorial below and deploy Pixtral Large Instruct 2411 on Hyperstack.
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Pixtral Large Instruct 2411:
Now, let's walk through the step-by-step process of deploying Pixtral Large Instruct 2411 on Hyperstack.
Initiate Deployment
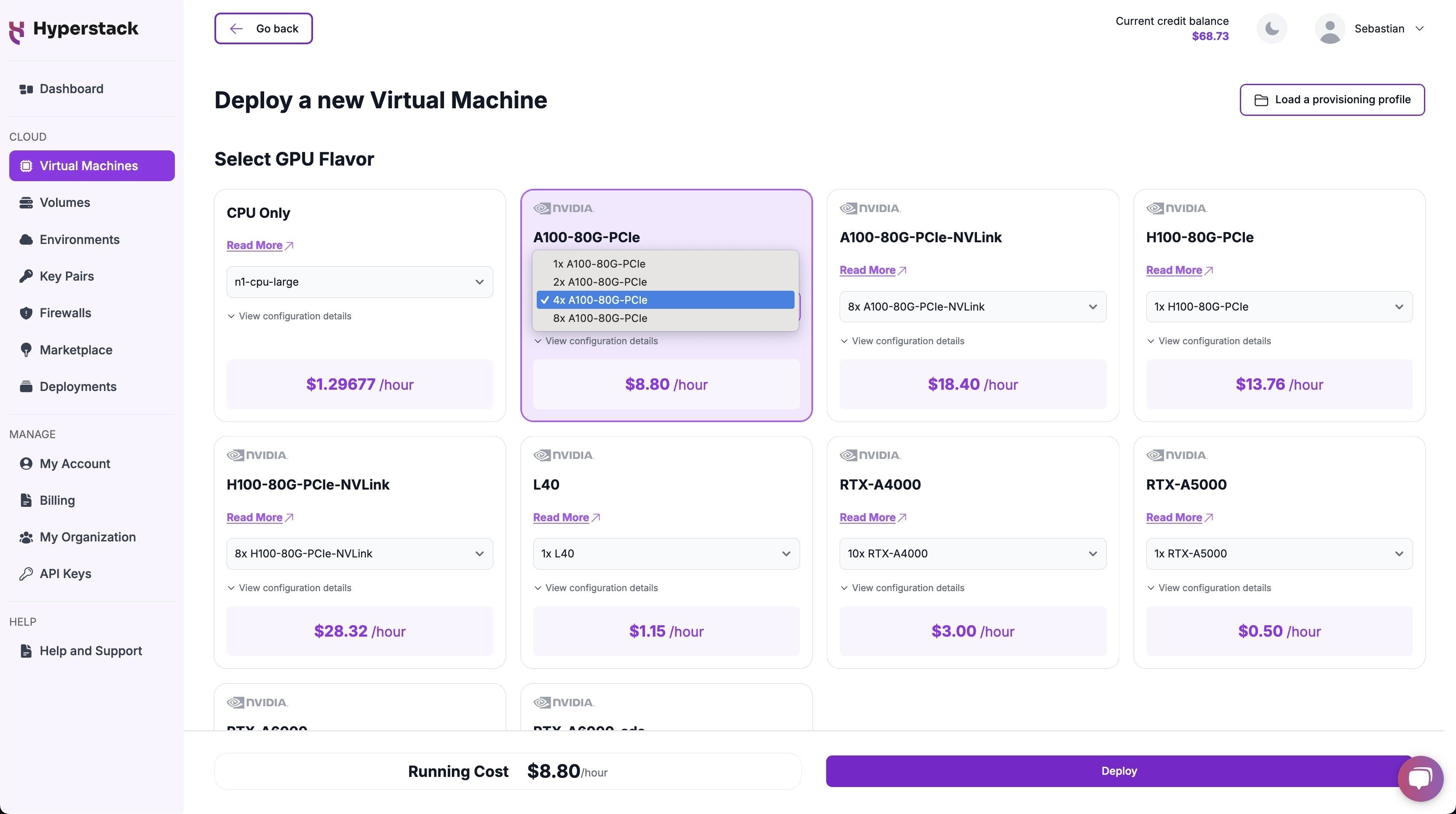
Select Hardware Configuration
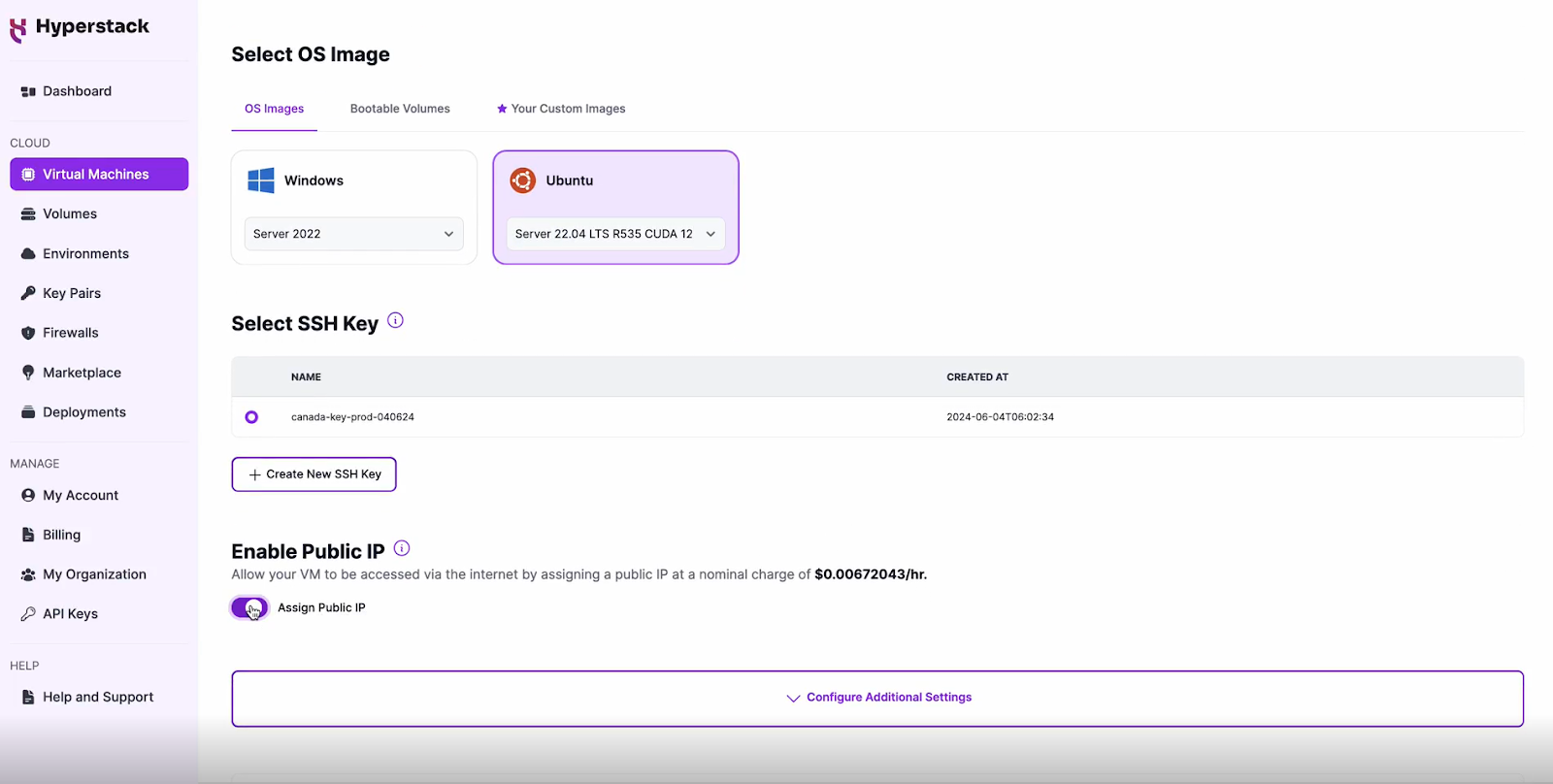
Choose the Operating System
Select a keypair
Network Configuration
Enable SSH Access
Configure Additional Settings
To use this model, you will need gated access:
Create a HuggingFace token to access the gated model, see more info here.
Replace line 11 of the attached cloud-init file with your HuggingFace token.
Review and Deploy
After deploying your VM, the cloud-init script will begin its work. This process typically takes about 7 minutes. During this time, the script performs several crucial tasks:
While waiting, you can prepare your local environment for SSH access and familiarise yourself with the Hyperstack dashboard.
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
To access and experiment with Meta's latest model, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Pixtral Large Instruct 2411.
# Query the model using an image
IMAGE_URL="https://www.hyperstack.cloud/hs-fs/hubfs/deploy-vm-11-ecd8c53003182041d3a2881d0010f6c6-1.png?width=3352&height=1852&name=deploy-vm-11-ecd8c53003182041d3a2881d0010f6c6-1.png"
cat < payload.json
{
"model": "mistralai/Pixtral-Large-Instruct-2411",
"messages": [
{
"role": "system",
"content": "SYSTEM_PROMPT"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe this image in two sentences"
},
{
"type": "image_url",
"image_url": {
"url": "${IMAGE_URL}"
}
}
]
}
]
}
EOF You should see a response similar to below:
{
"id": "chatcmpl-2b41dd5f00c44692a647f27c6526f397",
"object": "chat.completion",
"created": 1732088507,
"model": "mistralai/Pixtral-Large-Instruct-2411",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The image shows a virtual machine management interface from Hyperstack, where the \"genius-hubble\" VM is active. In the networking settings, the option to enable SSH access on port 22 is highlighted, and there are additional options for ICMP access and managing firewalls.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 2357,
"total_tokens": 2419,
"completion_tokens": 62,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
# Use the JSON payload file in the curl command
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d @payload.json
# Query the model only with text
cat < payload.json
{
"model": "mistralai/Pixtral-Large-Instruct-2411",
"messages": [
{
"role": "system",
"content": "SYSTEM_PROMPT"
},
{
"role": "user",
"content": "Hi. What can you do for me?"
}
]
}
EOF
# Use the JSON payload file in the curl command
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d @payload.jsonYou should see a response similar to below:
{
"id": "chatcmpl-eaadc212af354361b46ed65366f9f7a7",
"object": "chat.completion",
"created": 1732088556,
"model": "mistralai/Pixtral-Large-Instruct-2411",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! I can assist you with a wide range of tasks and provide information on various topics. Here are some examples:\n\n1. **Answer Questions**: I can provide information based on the data I've been trained on, up until 2023.\n\n2. **Explain Concepts**: I can help break down complex ideas into simpler parts to make them easier to understand.\n\n3. **Provide Suggestions**: Whether it's a book to read, a movie to watch, or a recipe to cook, I can provide recommendations.\n\n4. **Help with Language**: I can help with language translation, definition, or grammar.\n\n5. **Perform Simple Tasks**: I can do simple calculations, conversions, and other basic tasks.\n\n6. **Engage in Dialogue**: I can participate in conversations on a wide range of topics.\n\nWhat specifically would you like help with?",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 20,
"total_tokens": 221,
"completion_tokens": 201,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}If the API is not working after 20-30 minutes, please refer to our 'Troubleshooting Pixtral Large Instruct 2411 section below.
If you are having any issues, you might need to restart your machine before calling the API:
Run sudo reboot inside your VM
Wait 5-10 minutes for the VM to reboot
SSH into your VM
Wait ~3 minutes for the LLM API to boot up
Run the above API call again
If you are still having issues, try:
Run docker ps and find the container_id of your API container
Run docker logs [container_id] to see the logs of your container
Use the logs to debug any issues
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
To continue your work without repeating the setup process:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}