Qwen2.5-VL-32B-Instruct is an advanced 32-billion-parameter vision-language model from Alibaba's Qwen series. This model is designed to understand and generate both visual and textual content. It excels in recognising objects, analysing complex visuals like charts and layouts, and processing lengthy videos by identifying pertinent segments. The model can also accurately localise objects within images, offering structured outputs suitable for applications in finance and commerce.
The new qwen model has made more enhancements through reinforcement learning to improve its mathematical and problem-solving abilities, aligning its responses more closely with human preferences
The key features of Alibaba's latest Qwen2.5-VL-32B-Instruct model include:
Now, let's walk through the step-by-step process of deploying Qwen2.5-VL-32B-Instruct on Hyperstack.
Initiate Deployment
Select Hardware Configuration
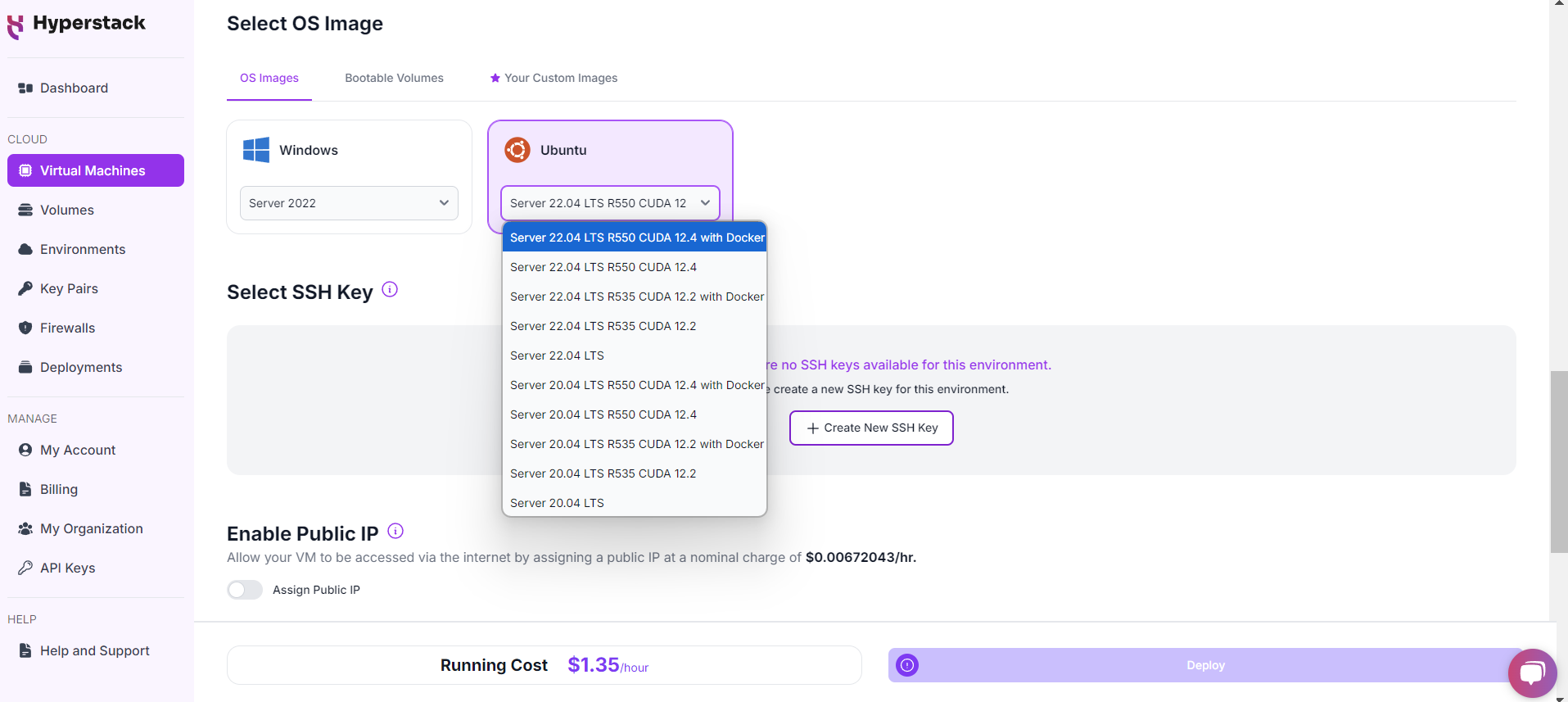
Choose the Operating System
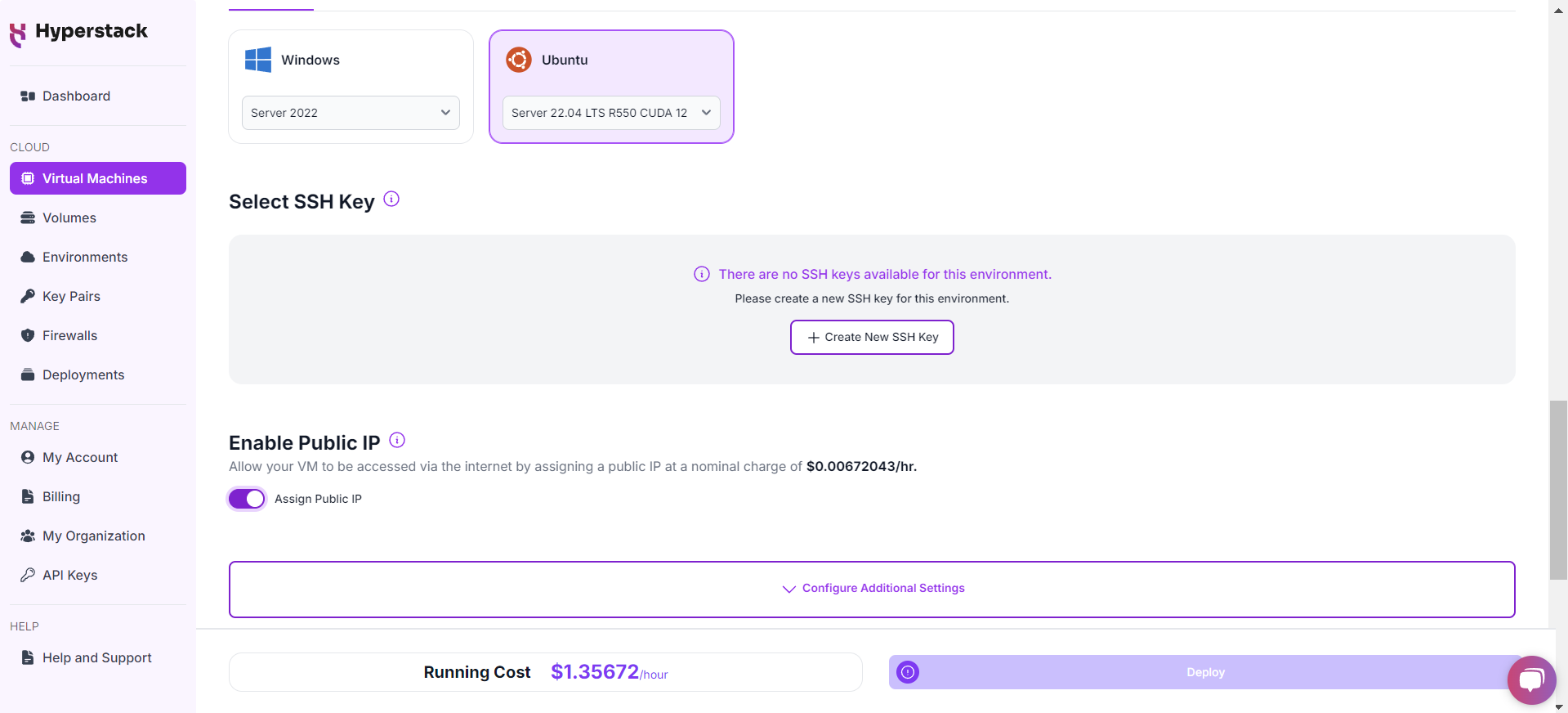
Select a keypair
Network Configuration
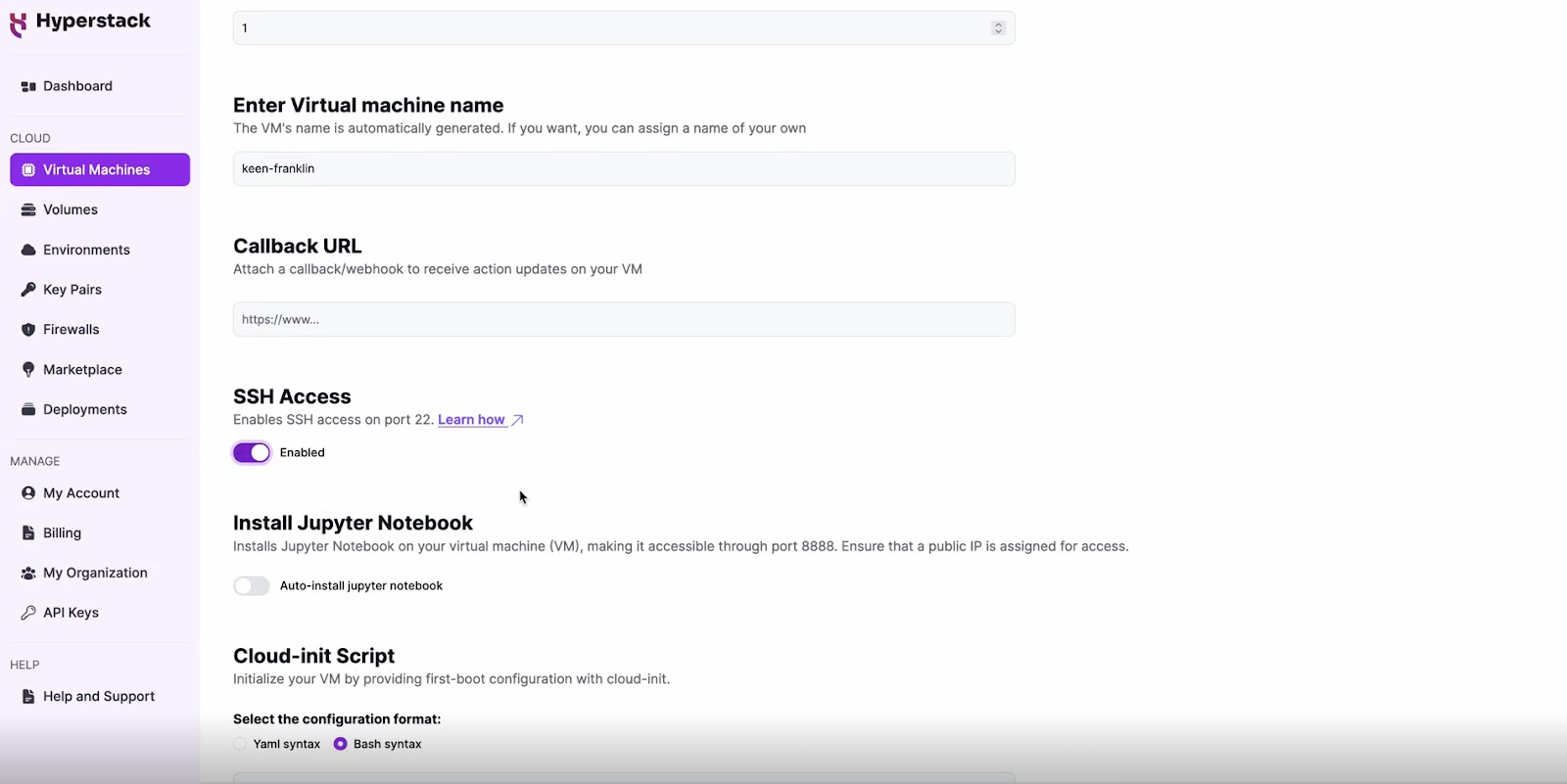
Enable SSH Access
Configure Additional Settings
Please note: this cloud-init script will only enable the API once for demo-ing purposes. For production environments, consider using containerization (e.g. Docker), secure connections, secret management, and monitoring for your API.
Review and Deploy
After deploying your VM, the cloud-init script will begin its work. This process typically takes about 5-10 minutes. During this time, the script performs several crucial tasks:
While waiting, you can prepare your local environment for SSH access and familiarise yourself with the Hyperstack dashboard.
Once the initialisation is complete, you can access your VM:
Locate SSH Details
Connect via SSH
To access and experiment with Qwen2.5-VL-32B-Instruct, SSH into your machine after completing the setup. If you are having trouble connecting with SSH, watch our recent platform tour video (at 4:08) for a demo. Once connected, use this API call on your machine to start using the Qwen2.5-VL-32B-Instruct:
IMAGE_URL="https://www.hyperstack.cloud/hs-fs/hubfs/deploy-vm-11-ecd8c53003182041d3a2881d0010f6c6-1.png?width=3352&height=1852&name=deploy-vm-11-ecd8c53003182041d3a2881d0010f6c6-1.png"
MODEL_NAME="Qwen/Qwen2.5-VL-32B-Instruct"
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "'$MODEL_NAME'",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe this image in two sentences"
},
{
"type": "image_url",
"image_url": {
"url": "'$IMAGE_URL'"
}
}
]
}
]
}
If you are having any issues, please follow the following instructions:
SSH into your VM.
Check the cloud-init logs with the following command: cat /var/log/cloud-init-output.log
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying Qwen2.5-VL-32B-Instruct:
New to Hyperstack? Log in to Get Started with Our Ultimate Cloud GPU Platform Today!
Qwen2.5-VL-32B-Instruct is a 32-billion-parameter vision-language model developed by Qwen, designed to understand and generate both visual and textual content.
The model excels in object recognition, analysis of complex visuals like charts and layouts, and processing lengthy videos by identifying pertinent segments. It can accurately localise objects within images and provides structured outputs suitable for applications in finance and commerce.
Compared to earlier models, Qwen2.5-VL-32B-Instruct has enhanced mathematical problem-solving abilities and improved performance in image parsing, content recognition and visual logic deduction tasks.
Yes, Qwen2.5-VL-32B-Instruct is open-sourced under the Apache 2.0 license.
The model is available on platforms like Hugging Face. You can access it through the Hugging Face repository here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}