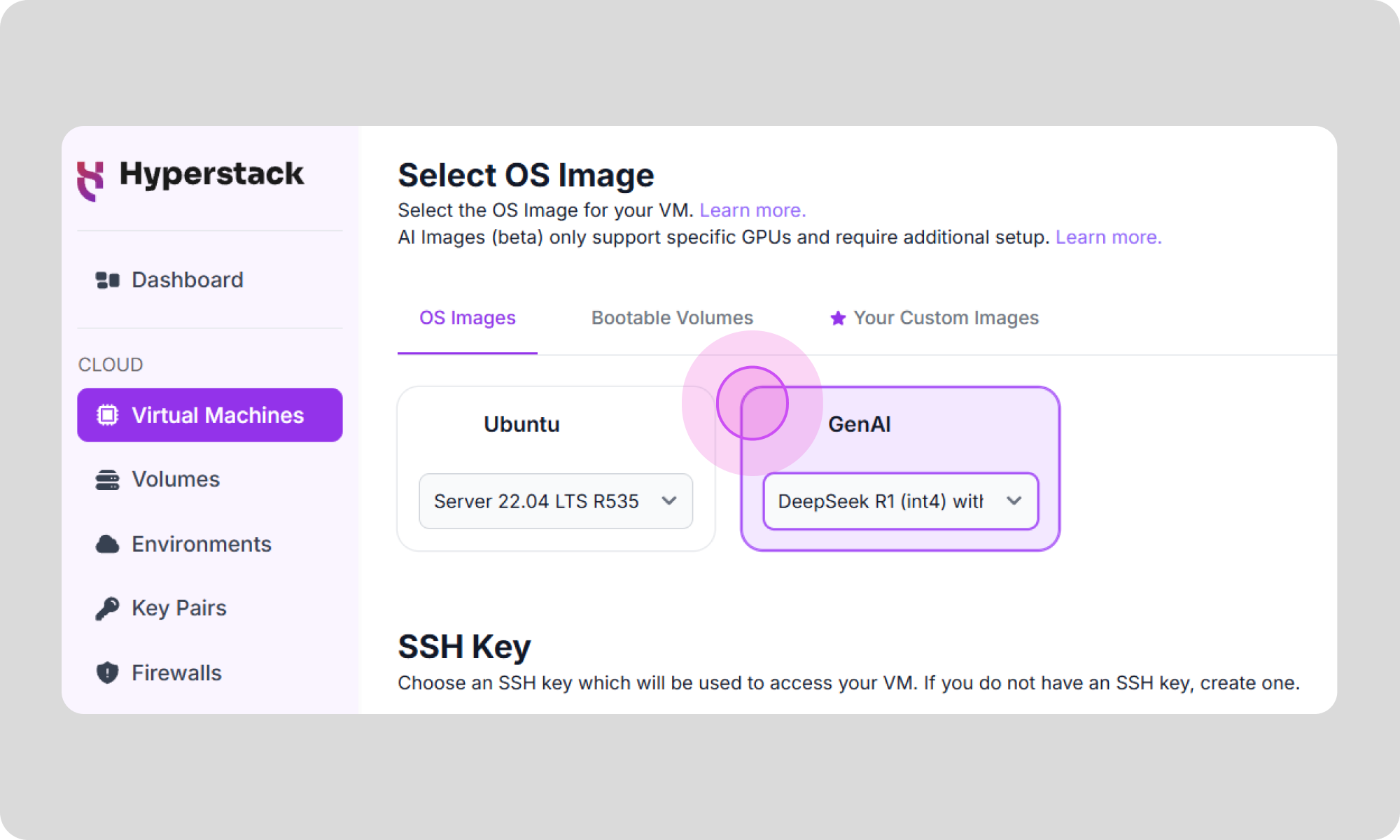
Great news! Hyperstack now offers a DeepSeek-R1 image (Beta) that lets you instantly deploy OpenWebUI with DeepSeek running on your machine. Simply select the 'DeepSeek' image from the list in the UI and your environment will be set up automatically—no manual configuration required.
IMPORTANT: Hyperstack's AI images are currently in Beta, and you may experience bugs or performance issues as we continue to refine them.
DeepSeek-R1 is a 671B parameter Mixture-of-Experts (MoE) open-source language model with 37B activated parameters per token and a 128K context length, designed for high performance, cost efficiency, and scalability. It excels in logical inference, mathematical reasoning, and structured problem-solving, leveraging reinforcement learning to enhance reasoning capabilities and generate coherent responses. DeepSeek-R1 integrates Multi-head Latent Attention (MLA) with DeepSeekMoE to optimise inference speed and training efficiency. It also introduces an auxiliary-loss-free load-balancing strategy and supports Multi-Token Prediction (MTP) for improved text generation accuracy. Released under the MIT license, DeepSeek-R1 is fully open-source, allowing free use, modification and redistribution.
Follow these steps to set up and run the DeepSeek-R1 image on Hyperstack:
Choose a suitable GPU configuration from the following options for your VM. The DeepSeek-R1 image has been successfully tested on the following GPU flavours. To ensure a smooth deployment, it is recommended to choose one of these flavours as selecting a different option may lead to deployment failure.
Disclaimer: This image automatically downloads and runs the INT4 quantised version of DeepSeek-R1, which is optimised to fit within a single machine. Refer to the model card here for further details.
Open your VM's firewall settings.
Allow port 3000 for your IP address (or leave it open to all IPs, though this is less secure and not recommended). For instructions, see here.
Visit http://[public-ip]:3000 in your browser. For example: http://198.145.126.7:3000
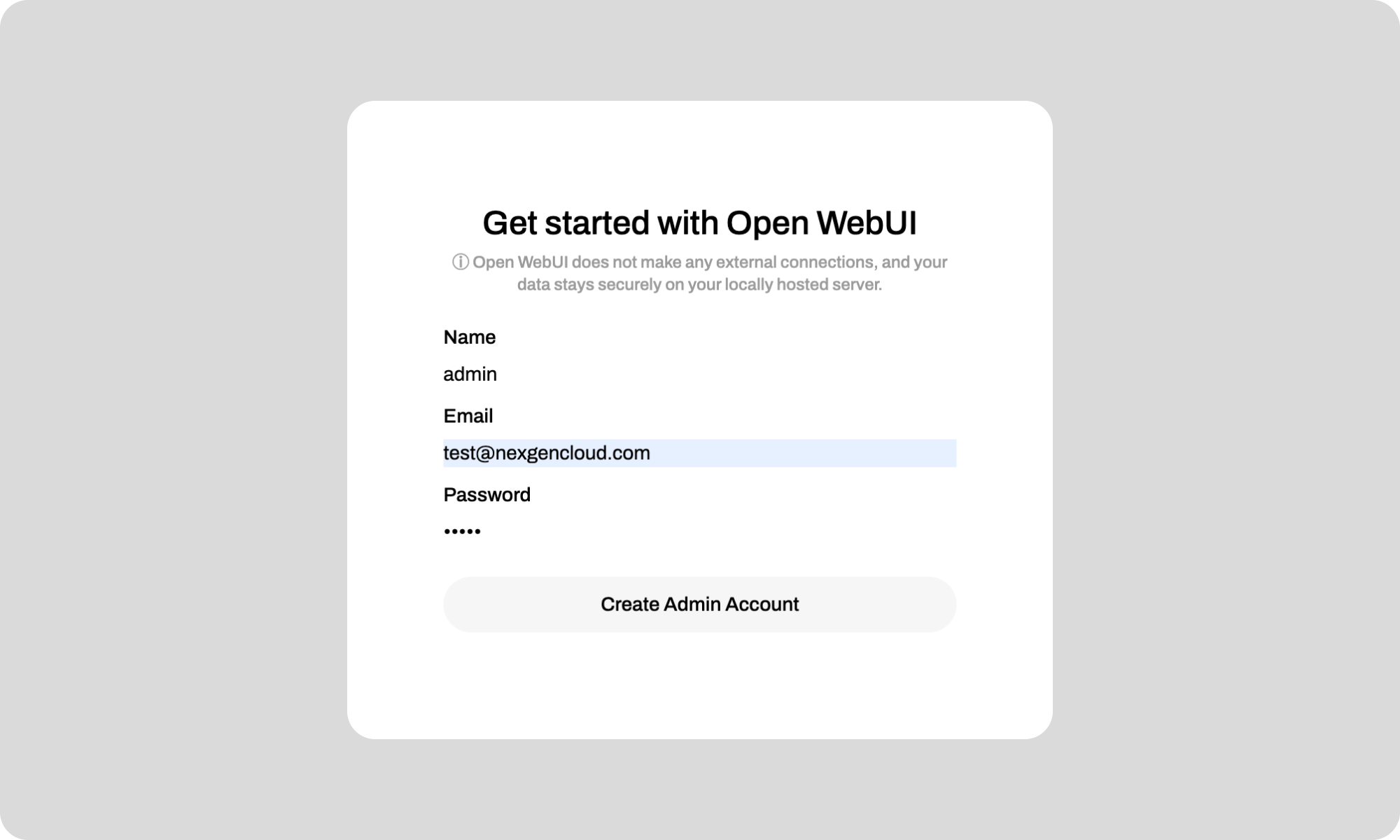
You can set up an admin account for OpenWebUI and save your username and password for future logins. See the attached screenshot.
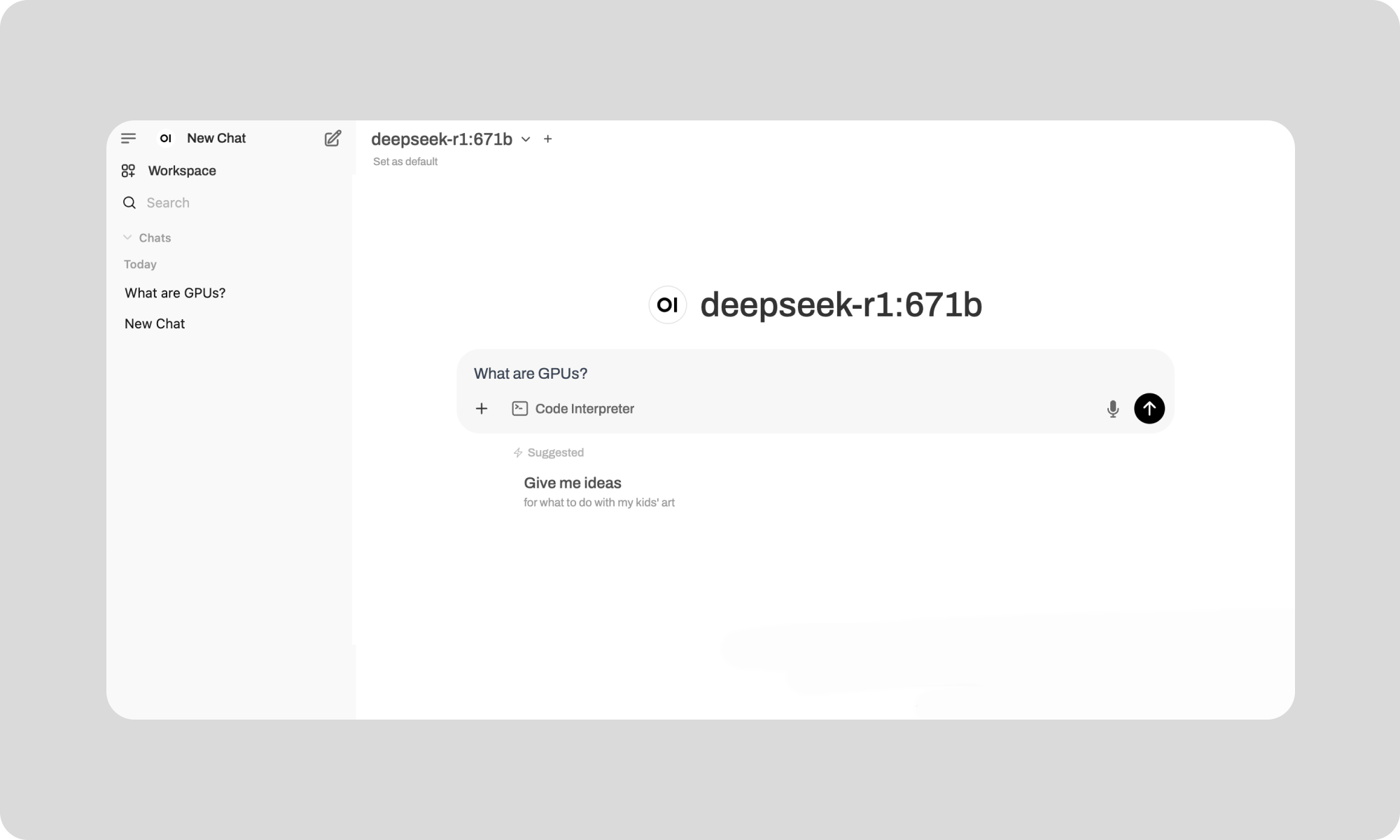
And voila, you can start talking to your self-hosted DeepSeek R1! See an example below.
The DeepSeek-R1 image comes with a default context size of 12,888 tokens. To modify it, follow these steps:
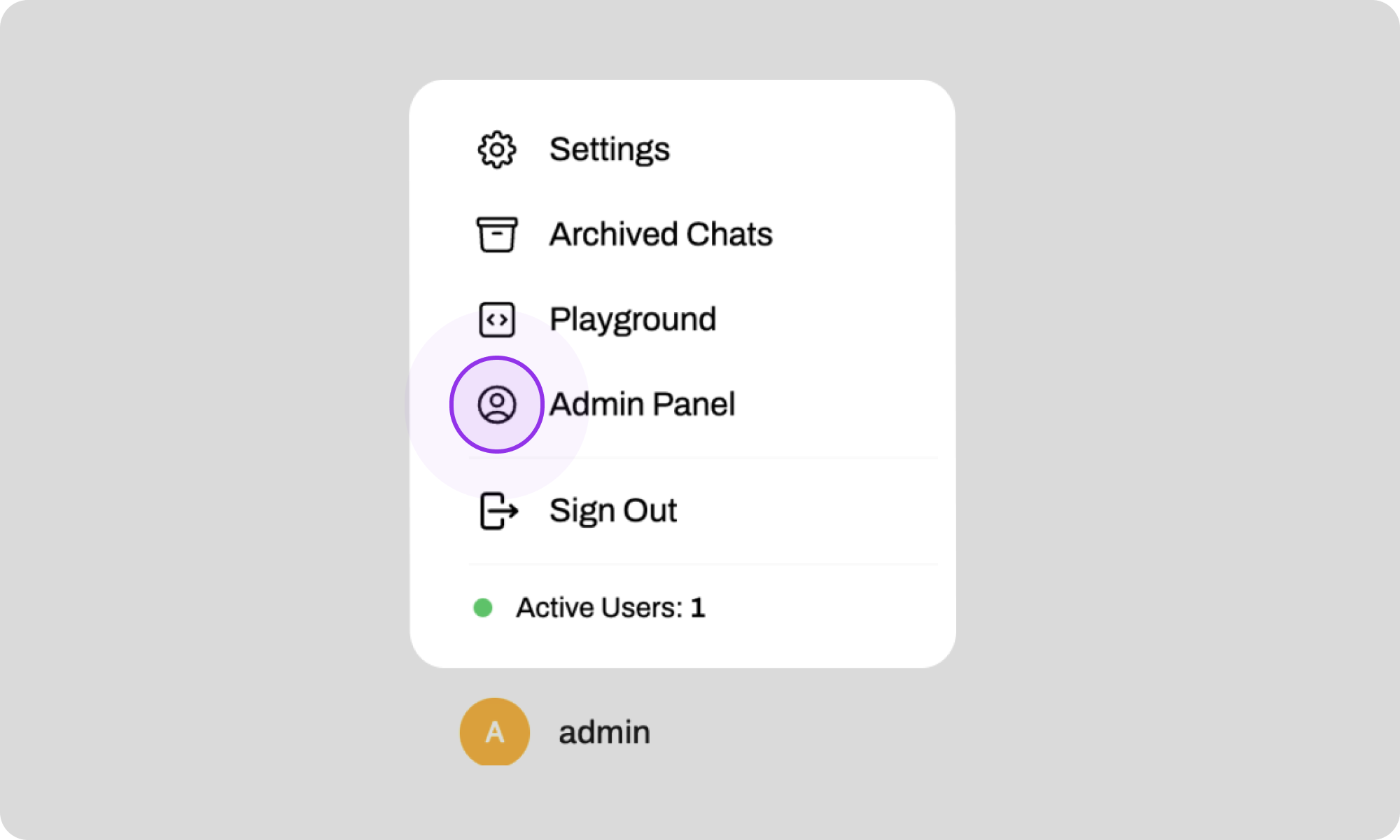
1. Click on your username at the bottom left and then on 'Admin Panel'.
2. Click on the "Settings" tab at the top.
3. Click on 'Models' in the left sidebar. This will take you to an overview of all the models available on your machine.
4. Click on the Pencil icon to the right of 'DeepSeek-r1-671B'.
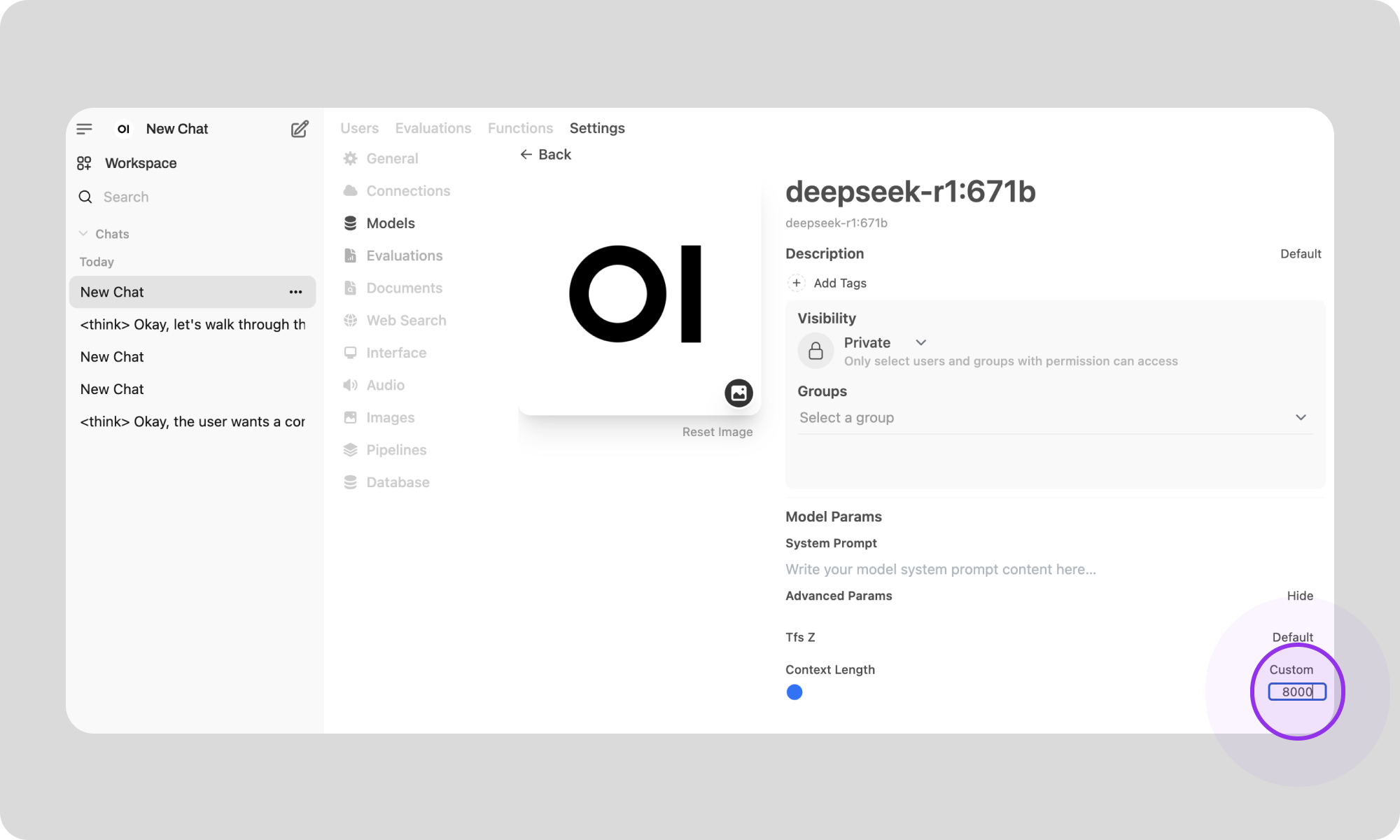
5. Click on 'Advanced params' to find the context length.
You can now customise the Context Length by entering a value that meets your requirements.
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
Hyperstack is a cloud platform designed to accelerate AI and machine learning workloads. Here's why it's an excellent choice for deploying DeepSeek-R1:
DeepSeek-R1 is a 671B parameter open-source Mixture-of-Experts language model designed for high-performance logical reasoning and problem-solving.
The key features of DeepSeek-R1 include:
To use the DeepSeek image, create a new VM on Hyperstack, select ‘DeepSeek’ from the OS Image dropdown. Once deployed, access OpenWebUI at http://[public-ip]:3000 to interact with DeepSeek-R1.
Choose a suitable GPU configuration from the following options for your VM. The DeepSeek-R1 image has been successfully tested on the following GPU flavours. To ensure a smooth deployment, it is recommended to choose one of these flavours as selecting a different option may lead to deployment failure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}