
TABLE OF CONTENTS

Updated: 11 Feb 2025
NVIDIA H100 SXM On-Demand
The Hyperstack LLM Inference Toolkit is an open-source tool designed to simplify the deployment, management and testing of Large Language Models (LLMs) using Hyperstack. Our toolkit is ideal for developers and researchers who need fast prototyping, intuitive API access and robust performance tracking. With seamless deployment options, streamlined proxy APIs and comprehensive model management, this toolkit accelerates LLM workflows for local and cloud-based setups.
Haven't heard about our LLM Inference Toolkit before? Check out our demo video below.
Want to get started with this toolkit? See our tutorial below. This tutorial provides a step-by-step guide to using the Hyperstack LLM Inference Toolkit, from setup to deploying your first LLM. You will need the files inside our Hyperstack LLM Inference Toolkit Repository/
LLM Inference Toolkit Tutorial Overview
Here's a quick overview of the steps involved in this tutorial:
- Prepare Your Environment: Install required tools like Docker.
- Choose Deployment Type: Opt for local or cloud deployment based on your needs.
- Deploy the Toolkit: Execute deployment commands to set up the toolkit.
- Interact with the Toolkit: Use the UI to deploy models, manage APIs, and monitor performance.
Prerequisites
Before proceeding, ensure you do the following:
- Download or clone our Hyperstack LLM Inference Toolkit repository here.
- Install Docker
- It is recommended to install Docker desktop (see instructions here).
- Install Docker Compose: See instructions here.
- Not needed if you have installed Docker desktop
- Install the Make utility:
- Windows: recommended to use Chocolately and then run command:
choco install make - Linux: run command:
sudo apt-get install build-essential - MacOs: Recommended to use Homebrew and run command:
brew install make
- Windows: recommended to use Chocolately and then run command:
How to Deploy the LLM Toolkit?
After installing the prerequisites, choose between local or cloud deployment based on your needs.
a. Local Deployment
To deploy the toolkit in a local environment (mostly to quickly get started and/or local development), follow these steps:
- Rename the
.env.examplefile to.env, which contains app configuration for the local environment. You can find this file in the repository shared above. - Change at least the following environment variables in the
.envfile:HYPERSTACK_API_KEY: Your Hyperstack API key (this will be needed if you decide to deploy any models on the 'Models' page through Hyperstack).APP_PASSWORD: The password for the User Interface (UI)
- Build and start app services containers in attached mode:
make dev-up
b. Cloud Deployment
To deploy the toolkit in a cloud environment, follow the steps below. Please note that this requires a Hyperstack account with an environment and keypair configured. See our Getting Started tutorial here.
- Rename the
deployment/build.manifest.yaml.examplefile todeployment/build.manifest.yaml, which contains app configuration for the cloud environment. You can find this file in the repository shared above. - Change at least the following environment variables in the
.envfile:env.HYPERSTACK_API_KEY: Your Hyperstack API keyenv.APP_PASSWORD: The password for the User Interface (UI)proxy_instance.key_name: Hyperstack keypair name for the Proxy VMinference_engine_vms.[idx].key_name: Hyperstack keypair name for the inference VMs
- Build and start the deployment:
make deploy-app
- Wait for the Proxy VM and the Inference VMs to boot up. Note: first the Proxy VM will be created and configured. Afterwards, the Inference VMs will be created and configured.
- By default, the toolkit deploys the VMs described below. You can change the default deployment by following the instructions here.
- A proxy VM for routing requests and hosting the UI.
- Two inference VMs with preloaded models:
- NousResearch/Meta-Llama-3.1-8B-instruct
- microsoft/Phi-3-medium-128k-instruct
For more instructions on different build commands, check out our user documentation on GitHub.
How to use the LLM Inference Toolkit
To interact with the toolkit using the User Interface, you can open the LLM Inference Toolkit via:
- http://localhost:8501 (for Local deployment)
- http://[public-ip-proxy-vm]:8501 (for Cloud deployment)
- You can find the public IP of your Proxy VM via https://console.hyperstack.cloud/virtual-machines (see screenshot below)
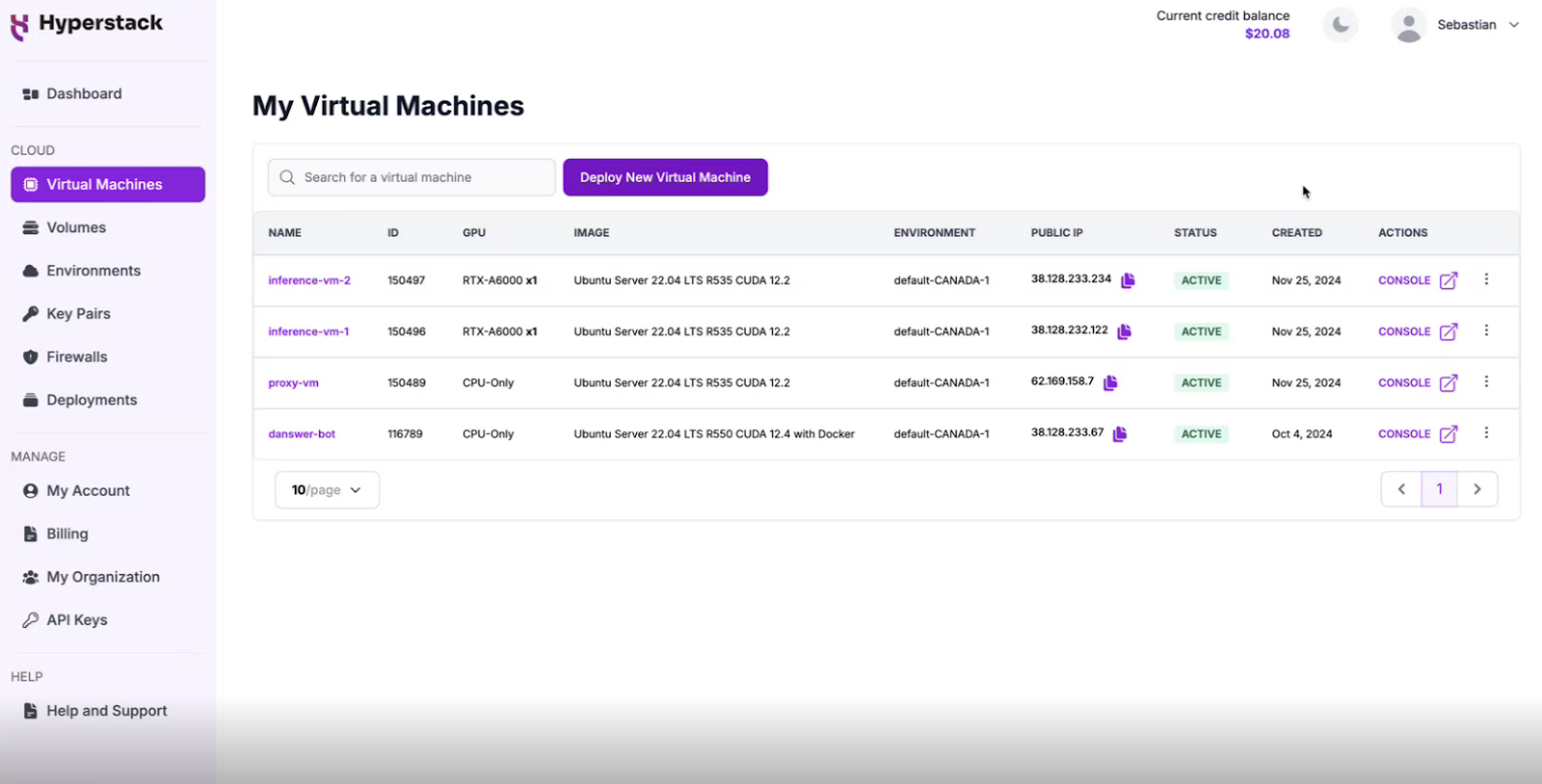
After opening the URL above, you need to enter the App Password you have set in the previous step.
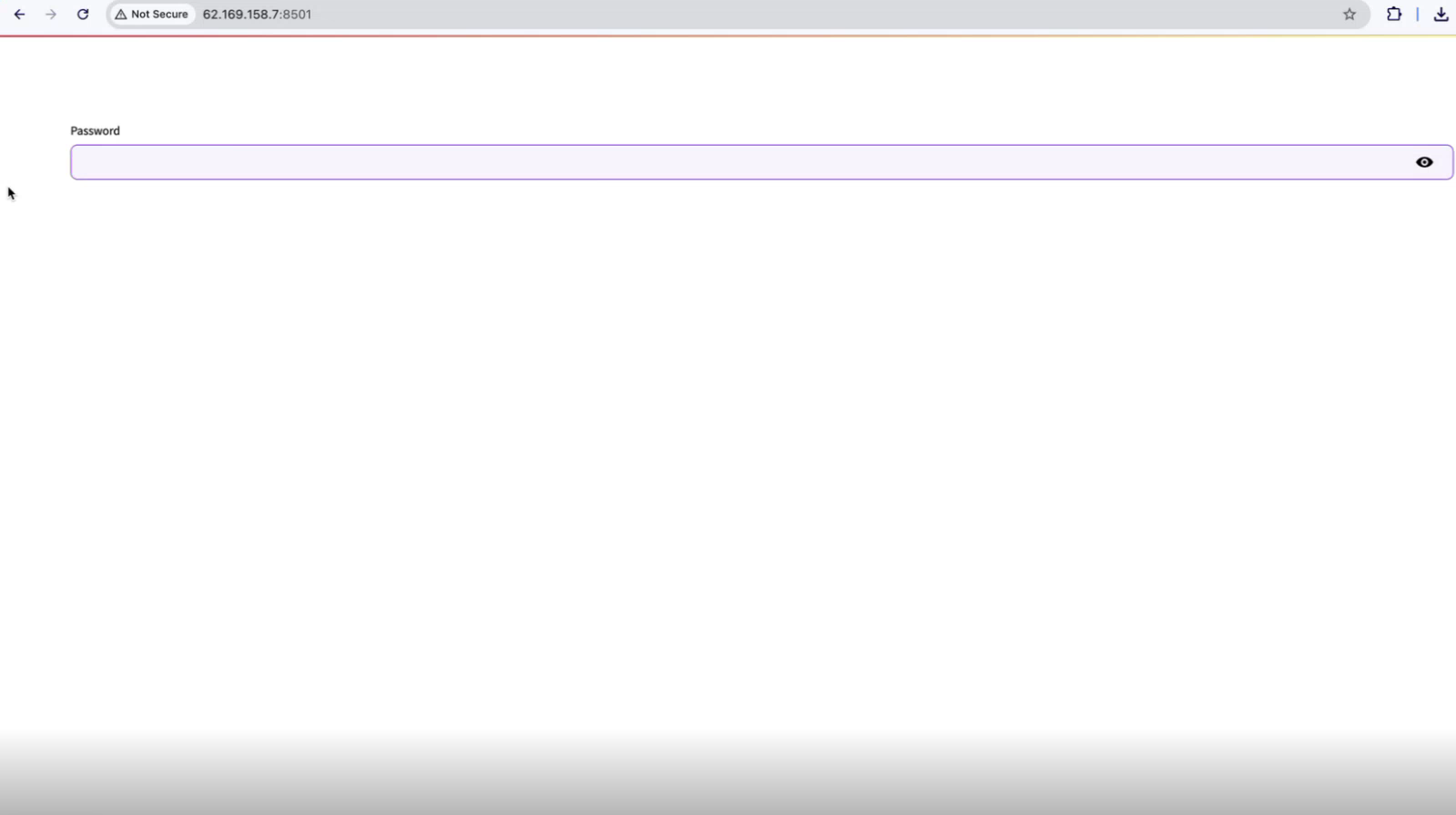
Please note: the current implementation does not utilize SSL for secure data transmission. Until SSL support is added, exercise caution and avoid transmitting sensitive or confidential data through the toolkit over the internet.
a. Playground
After opening the LLM Inference Toolkit, you can select "Playground" to get started with your LLMs. This page allows you to interact with one of your deployed LLMs model.
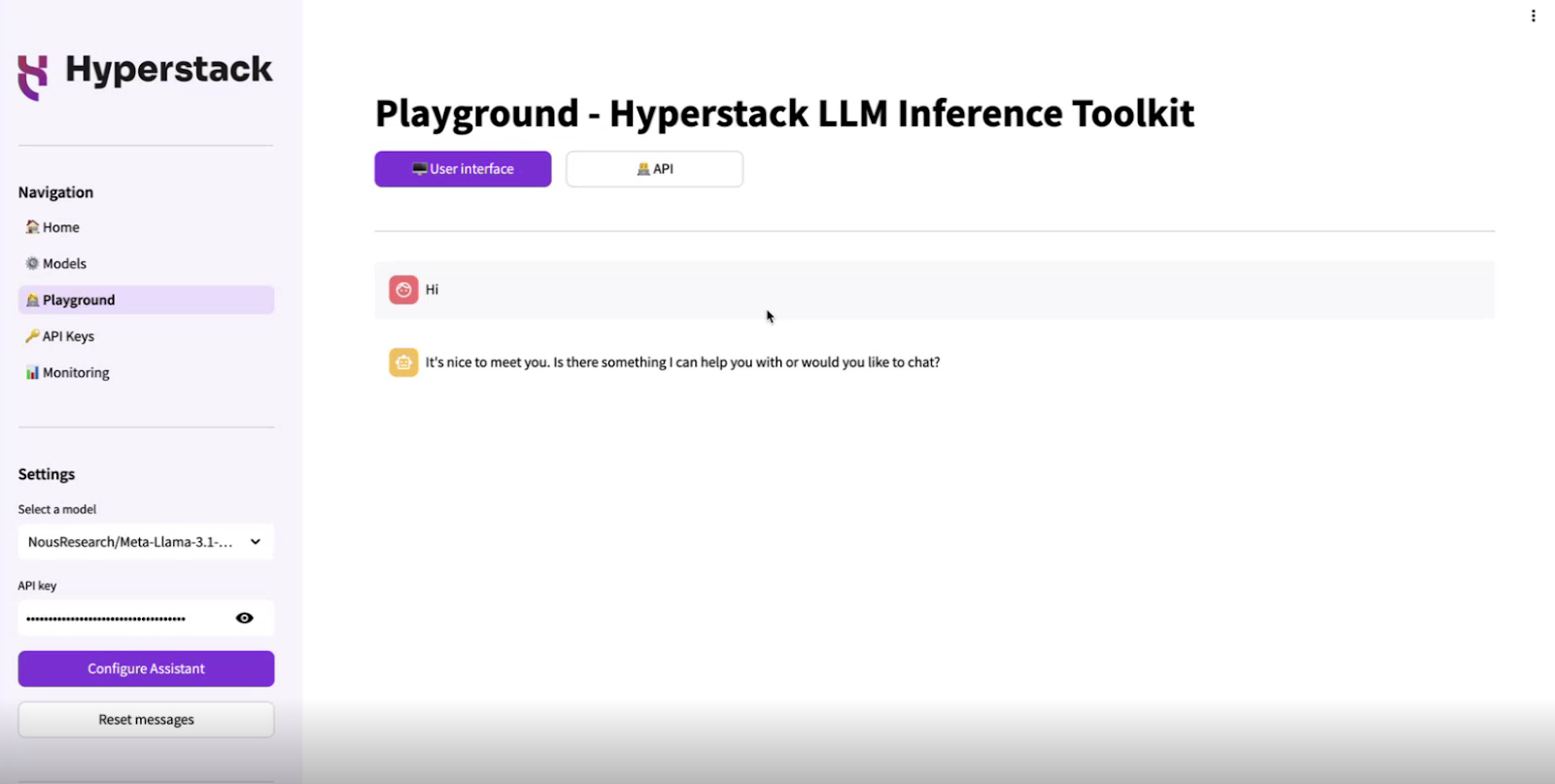
Instructions
- Select a Model: Choose a model from the sidebar to chat with.
- Enter Your Message: Type your message in the chat input box at the bottom of the page.
- Configure Assistant: Click the "Configure Assistant" button in the sidebar to change advanced settings such as temperature, max tokens, and presence penalty.
- Chat with Assistant: Once you've selected a model and entered your message, click the ">" button to start chatting with the assistant.
Additional Tips
- You can stream the response from the API by checking the "Stream results" checkbox in the configure assistant dialog.
- You can reset all previous conversations by clicking on the "Reset messages" button in the sidebar.
- By default, the
User_ID = 0(default user) is used for interacting with the API.
b. Models page
This page allows you to view all deployed LLMs, add new models, and manage replicas for each model.

Instructions
- View Models: See all your deployed models listed on this page.
- Add New Model: Use the "Add New Model" section to deploy a new model.
- For more info on deploying a new LLM, check out our user documentation on GitHub.
- Manage Replicas: For each model, you can add, edit, or delete replicas.
- Add Replica: Click the "Add" button under a model to create a new replica. You can either provide an existing endpoint or deploy a new replica on Hyperstack.
- Delete Replica: Click the "Delete" button next to a replica to remove it. See warning note below.
- Delete Model: Click the "Delete" button next to a model to remove it. See warning note below.
Additional Tips
- You can refresh the status of the replica by clicking on the 'Refresh' icon on the right side of the model name.
- Make sure your model name matches the model name used by the inference engine such as vLLM. For example:
NousResearch/Meta-Llama-3.1-8B-Instruct. - When deploying a new replica on Hyperstack, make sure to view the help (?) icon for more information.
Warning
- Deleting a model or replica will only delete it from the database. Any cloud resources may still exist and incur billing costs.
c. API key management
This page allows you to create an API key for your user ID and view existing API keys. This API key can be used to interact with the chat/completion API endpoint.
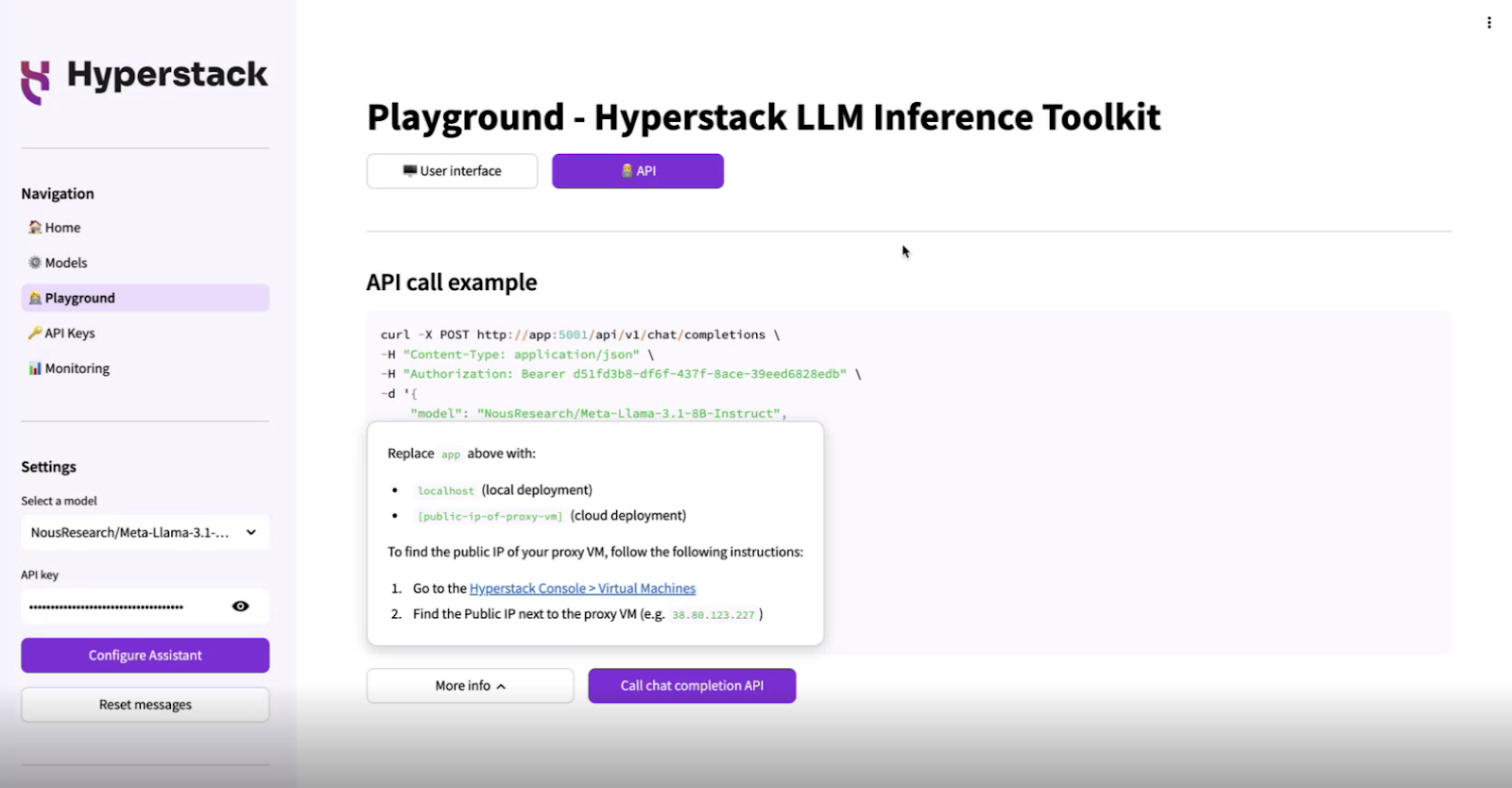
Instructions
- Enter User ID: Input the user ID for which you want to generate an API key.
- Generate API Key: Click the "Generate API key" button to create a new API key.
- Delete API Key: Click the "Delete API key" button to remove an existing API key.
- View API Keys: Existing API keys will be displayed in a table below.
Additional Tips
- API keys can only be deleted if they have not been used yet.
- API keys that have been used can only be disabled.
d. Monitoring
This page allows you to view and interact with the data stored in your databases.
User Instructions
- Select a Table: Choose a table from the dropdown list to view its data.
- View Data: The data from the selected table will be displayed in a table format.
- Download CSV: You can download the data as a CSV file by clicking the download button.
Additional Tips
- You can refresh the data by re-selecting the table from the dropdown list.
- Metrics data may not be stored correctly for locally or externally deployed models.
Conclusion
We hope this tutorial helps you make the most of your LLM model with the Hyperstack LLM Inference Toolkit. Stay tuned for more developer-friendly resources to simplify your AI workflows. We’re here to make AI easy for you!
Want to Get Started with Latest Hyperstack Features? Check out our tutorials below:
FAQs
What is the Hyperstack LLM Inference Toolkit?
The LLM Inference Toolkit is an open-source tool that simplifies the deployment, management, and testing of Large Language Models (LLMs) using Hyperstack.
What models does the Hyperstack LLM Inference Toolkit support?
It supports open-source LLMs with flexible deployment options for local or cloud setups.
Does the toolkit include pre-built integrations for vLLM?
Yes, it provides proxy API integrations optimized for vLLM, ensuring high throughput and low latency.
Can I track real-time model performance?
Yes, our toolkit offers real-time tracking, including visualised data and usage insights.
Is the LLM Inference Toolkit secure?
Yes, it includes built-in password protection and API key enforcement for security.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 7 Apr 2025
7 Apr 2025