.png)
TABLE OF CONTENTS

Updated: 11 Feb 2025
Apple's DCLM models are currently the top-performing and truly open-source models. But what does Apple mean by truly open source? How is that any different from other prominent open-source models? By truly open-source, Apple implies that all the weights, training codes and datasets are freely accessible alongside the model.
It's unexpected to see Apple leading the AI race, particularly with fully open-sourced models, while even prominent AI leaders like OpenAI don't release open-source models. Yet, Apple has introduced its latest 7B parameter model for anyone to use or adapt. The DCLM-7B has already outperformed Mistral-7B in certain benchmarks and is reaching performance levels comparable to similar models from Meta and Google.
What is DCLM?
Developed by the DataComp for Language Models (DCLM) team, DCLM-Baseline-7B is a 7 billion-parameter language model that shows the impact of systematic data curation. This decoder-only Transformer, primarily trained on English text, is available under the Apple Sample Code License. The model was released in June 2024 and all its relevant code, instructions and models can be accessed through its GitHub repository.
What are the Features of DCLM-7B?
The DCLM-7B is considered one of the best-performing open-source language models and here’s why:
- Model Specifications: The 7B base model is trained on 2.5 trillion tokens, primarily using English data with a 2048 context window. This ensures a rich understanding of language nuances and context for accurate and insightful text generation.
- Training Data: The model incorporates datasets from DCLM-BASELINE, StarCoder and ProofPile2. So, it can perform a wide range of language tasks including general, Math and programming tasks.
- Performance: The model has achieved an MMLU score of 0.6372, which makes it a high-performing open-source language model.
- License: The model is distributed under an open license, specifically the Apple Sample Code License that allows for commercial usage.
- Training Framework: The model is built using PyTorch and the OpenLM framework.
-
Availability: The model is available on Hugging Face and integrated with Transformers. So you get easy access and seamless integration into various NLP workflows.
How Does the DCLM-7B Perform?
The DCLM-7B model shows strong performance in various benchmarks, particularly when compared to other models in the 7B parameter range. Here is a detailed breakdown of its performance metrics:
.jpg?width=499&height=500&name=Info%2013%20(1).jpg)
Performance Metrics of DCLM-7B
The performance metrics of DCLM-7B are as mentioned below:
- CORE: The CORE evaluation for a model is an extensive assessment designed to measure its performance across various challenging tasks. These tasks are sourced from different domains and are meant to evaluate multiple benchmarks like HellaSwag, Big-Bench, OpenBookQA etc. The DCLM-7B score is 56.1, indicating robust core capabilities.
- MMLU: With a score of 63.7, it performs exceptionally well on the Massive Multitask Language Understanding (MMLU) benchmark, suggesting a high proficiency in understanding and processing diverse language tasks.
- EXTENDED: The EXTENDED evaluation measures a model's performance on complex and comprehensive tasks beyond the fundamental capabilities. It includes benchmarks across various tasks such as BBQ, Big-Bench, GSM8K, Math QA and more. The model scores 43.6, showing progress in more complex and comprehensive tasks
Comparative Analysis of DCLM-7B
When compared to other 7B models, DCLM-7B stands out in several key areas:
Open Weights, Closed Datasets:
- Models like Llama 3, DeepSeek and Phi-3 use closed datasets, meaning their training data is not publicly accessible. In contrast, DCLM-7B offers more transparency and accessibility with its open dataset.
- DCLM-7B's CORE score (56.1) is higher than Llama 2 (49.2) and DeepSeek (50.7). However, it doesn't outperform Llama 3 i.e. 57.6 so there is room for improvement.
Open Weights, Open Datasets:
- Among models with open datasets, DCLM-7B's MMLU score (63.7) surpasses other models such as Falcon (27.4) and OLMo-1.7 (54.0), indicating a significant advantage in language understanding tasks.
- The EXTENDED score of 43.6 also places DCLM-7B ahead of models like MAP-Neo (40.4), demonstrating enhanced performance in more complex scenarios.
How to Get Started with DCLM-7B on Hyperstack?
Before getting started with DCLM-7B, make sure you have set up your account (see instructions here).
Step 1: Launch a New Virtual Machine
Once you have an account, you can launch a new VM on Hyperstack:
- Log in to your Hyperstack account.
- Navigate to the Hyperstack Dashboard
- Go to the 'Virtual Machines section in Hyperstack and click Deploy New Virtual Machine.

Step 2: Select the Configuration
Now you can launch a new Virtual Machine.
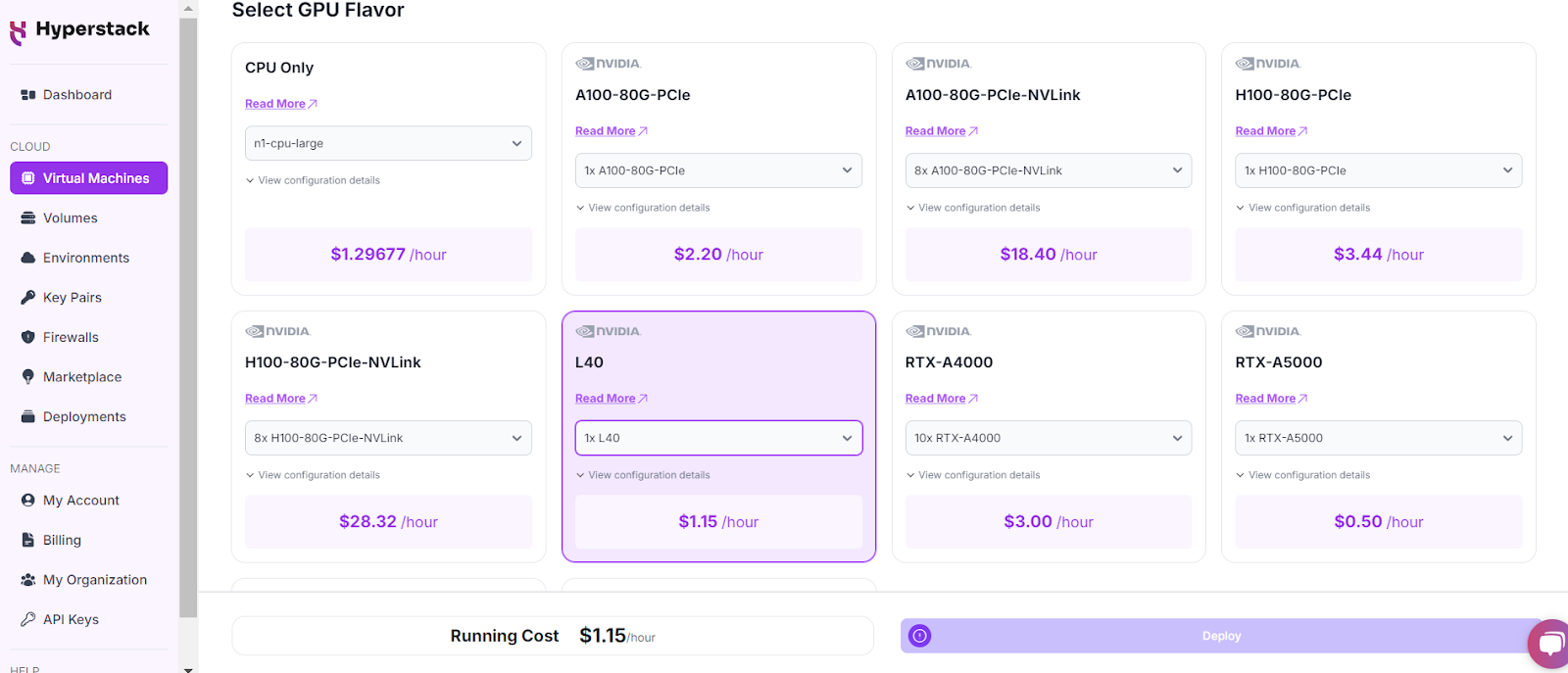
- Select the configuration with NVIDIA L40 GPU.
- Choose the appropriate flavour type based on your workload. Learn more about Hyperstack flavours here.
- Click "Deploy" to start the Virtual Machine.
For inference on full precision (float32), we recommend NVIDIA L40 as this model requires +- 30GB GPU vRAM.
Also Read: How to Run Jupyter Notebooks Like a Pro on Hyperstack
Step 3: Install Required Packages
SSH into your machine (see instructions here). Now, install the required packages as mentioned below:
#install python3-pip and python3-venv
sudo apt update -y
sudo apt install python3.10-venv python3-pip -y
#optionally, create a new virtual environment and activate it
python -m venv .env
source .env/bin/activate
#install transformers
pip3 install transformers
#install open_lm
pip3 install git+https://github.com/mlfoundations/open_lm.git
Step 4: Run inference
The Python code below downloads the model and runs inference. Please note that we explicitly move the model and input to the Cuda device.
from open_lm.hf import *
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("apple/DCLM-Baseline-7B")
model = AutoModelForCausalLM.from_pretrained("apple/DCLM-Baseline-7B").to('cuda')
inputs = tokenizer(["Machine learning is"], return_tensors="pt").to('cuda')
gen_kwargs = {"max_new_tokens": 50, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(inputs['input_ids'], **gen_kwargs)
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)
Does DCLM-7B Have Limitations?
While DCLM-Baseline-7B is a strong and capable model, it does have some limitations that you should be aware of:
- Potential Biases: The model, like other models trained on publicly available datasets, may contain biases
- Lack of Safety Fine-Tuning: Since the model hasn't undergone specific alignment or safety fine-tuning, use its outputs with caution.
- Task Performance Variability: The model's performance may differ on tasks not included in the evaluation suite.
- Knowledge Cutoff: The model's information is restricted to the data available up to its training cutoff date.
- Ethical Use: DCLM-7B, like other large language models, might generate harmful or biased content and should not be used for decisions about individuals or sensitive applications without proper safeguards and human oversight.
Sign up now to get started with Hyperstack. To learn more, you can watch our platform demo video below:
Explore our latest tutorials on Deploying and Using SAM 2 and Qwen2-72B on Hyperstack.
FAQs
What framework is used to train DCLM-7B?
DCLM-7B is trained using PyTorch with OpenLM.
Where can I find the DCLM-7B model and dataset?
The model is available on the DCLM GitHub Repository and the dataset on Hugging Face.
What is the total number of training tokens used for DCLM-7B?
DCLM-7B was trained on a total of 2.5 trillion tokens.
Are there any specific ethical considerations when using DCLM-7B?
Yes, be aware of potential biases in the training data and ensure responsible usage with appropriate safeguards.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 11 Apr 2025
11 Apr 2025