Running AI applications on Docker containers can visibly improve your workflow by offering scalability and easy management of dependencies. If you're already using Hyperstack's GPU-as-a-Service platform, deploying Docker containers for AI workloads becomes even more seamless, thanks to our powerful infrastructure designed for high-performance computing. In this guide, we'll walk you through the process of running Docker containers on Hyperstack to accelerate your AI applications.
Running a docker container is considered an ideal solution when managing complex AI workloads. Here’s why you should consider using Docker containers for your AI projects:
Portability: Docker containers package your AI applications and their dependencies into a standardised unit. This ensures your application runs consistently across various environments without compatibility issues.
Isolation: Docker containers provide isolated environments for running large AI models, ensuring that dependencies, libraries, and configurations specific to each model or project do not conflict. This is particularly important when managing multiple large models that require different frameworks, versions, or custom configurations, allowing you to maintain stability and consistency in your workflows.
Simplified Deployment: Docker simplifies the deployment of AI applications by offering a consistent environment for testing, building and production. It is ideal for continuous integration and deployment (CI/CD) pipelines so you can quickly and reliably move AI models from development to production.
Before you can start deploying Docker containers, ensure that you have a Hyperstack account and access to the required resources such as our NVIDIA GPUs. Follow the below steps to get started:
Log in or Sign up with your Hyperstack account here: https://console.hyperstack.cloud/
Go to the 'Virtual Machines' page in Hyperstack and click on "Deploy New Virtual Machine." Select the configuration for the virtual machine based on your requirements.
Note: Hyperstack also offers NVLink and high-speed networking options for NVIDIA A100 and NVIDIA H100 with NVLink, making them perfect for AI applications requiring heavy parallel processing and faster data transfer. You can choose among these options on Hyperstack according to your specific needs.
Once you have added your virtual machine, follow the below steps to configure additional settings:
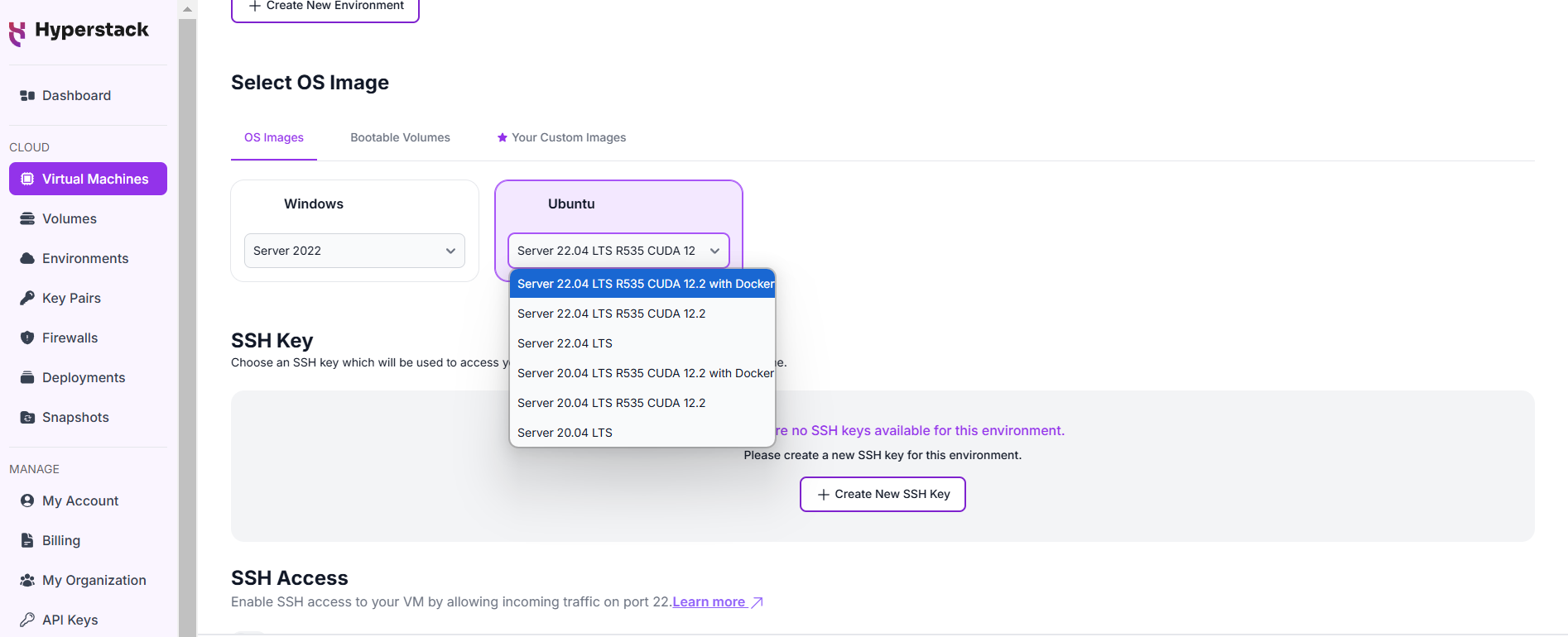
1. Scroll to the bottom of the virtual machine deployment page and you will see the "select OS Image" option.
2. Select the "Ubuntu Server 22.04 LTS R535 CUDA 12.2 with Docker" image option under the Ubuntu dropdown.
Once you’ve selected the image, click "Deploy" to create your virtual machine. The process will begin and your virtual machine will be provisioned with the necessary Docker setup.
After your virtual machine is deployed and in an ACTIVE state, verify the successful installation of Docker and NVIDIA GPU support. Run the following command to confirm:
docker run -it --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi If the installation is successful, you will see an output similar to the output below:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A6000 On | 00000000:00:05.0 Off | Off |
| 30% 36C P8 8W / 300W | 1MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
And voila, your virtual machine is ready to use Docker containers for your AI applications.
Want to make use of your Docker with GPU capabilities? Follow the below steps to deploy an LLM:
Step 1: Set Up Docker with GPU Support: We are using Docker with GPU capabilities to deploy a large language model efficiently. Ensure your system supports this configuration.
Step 2: Choose the Right GPU: We are deploying the Llama 3.1 8B model (you will need at least 17GB of GPU memory). For this, we are using GPUs like the NVIDIA L40 or RTX A6000, as they are well-suited for this workload.
Step 3: Deploy the Model: We are running the following command to deploy the Llama 3.1 8B Large Language Model using Docker with GPU support.
mkdir -p /home/ubuntu/data/hf
docker run -d --gpus all \
-v /home/ubuntu/data/hf:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host --restart always \
vllm/vllm-openai:latest --model "NousResearch/Meta-Llama-3.1-8B-Instruct" \
--gpu-memory-utilization 0.9 --max-model-len 15360 --chat-template examples/tool_chat_template_llama3.1_json.jinja
Please note: The above script deploys the NousResearch version of Llama-3.1-8B. This allows you to get started with Llama-3.1-8B without a HuggingFace account and HuggingFace token.
Running Docker containers on Hyperstack is an efficient and scalable solution for deploying AI applications. With Hyperstack's high-performance infrastructure, including NVIDIA GPUs, NVLink and high-speed networking options, you can easily manage resource-intensive AI workloads and achieve faster, more reliable results. By following the easy steps shared in this guide, you'll be able to deploy Docker containers seamlessly and optimise your AI applications for performance and scalability.
Yes, you need to create a Hyperstack account to access the platform and deploy virtual machines for running Docker containers.
After deploying your virtual machine, you can run a simple verification command to check if Docker and NVIDIA GPU support are correctly installed. If successful, the command output will confirm the installation.
Yes, Hyperstack provides a pre-configured Docker script (find the cloud-int script here) that installs necessary Docker packages and runs a test container that uses your NVIDIA GPUs. You can easily integrate this into the cloud-init configuration during the VM setup.
{kind=link}
{kind=link}
{kind=link}