
TABLE OF CONTENTS

Updated: 11 Feb 2025
NVIDIA H100 SXM On-Demand
Running Jupyter Notebooks locally can be frustrating - especially when working with large datasets or resource-intensive models like deep learning. You may resort to tricks like quantised models or C++ implementations just to squeeze more performance out of your consumer hardware. But there's a better way.
Cloud platforms with GPUs can take your jupyter notebooks to the next level, providing scalable computational power you simply can't match locally. However, cloud resources can be complex and expensive to manage. That's where Hyperstack comes in. We make it easy to spin up a Jupyter environment in the cloud with all the GPU acceleration you need. No managing infrastructure, no hidden charges. Hyperstack’s flexible cloud GPU pricing means you only pay for exactly what you use.
In this quick tutorial, we'll demonstrate how Hyperstack eliminates the pain of local notebooks and creates professional-grade capabilities. Whether you're just prototyping ideas or working with massive datasets, Hyperstack gives you the ability to run notebooks like a pro. Let's get started!
1. How to Launch a VM on Hyperstack
First, we'll launch a Virtual Machine (VM) on Hyperstack with the power we need:
a. Go to the Hyperstack platform.

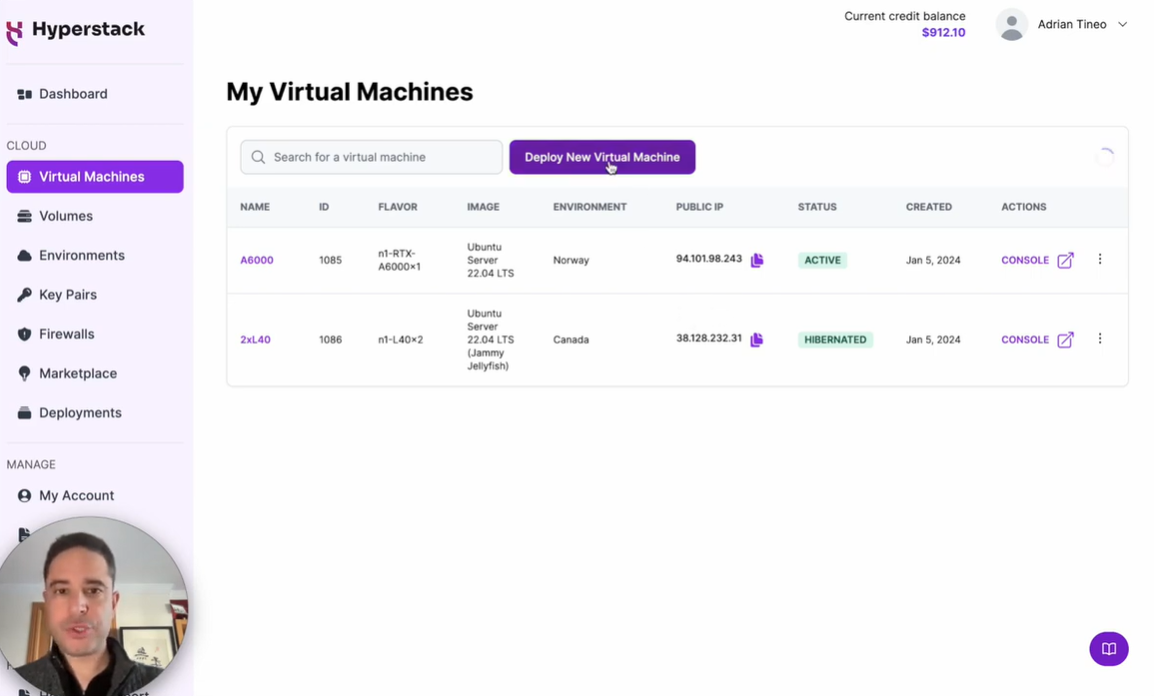
b. Click on “Deploy New Virtual Machine” to create a new virtual machine.
c. Name the virtual machine (e.g., 'Kandinsky').

d. Choose the data centre location (e.g., Norway Center).

e. Select the machine type (e.g., Nvidia RTX A6000 GPU).

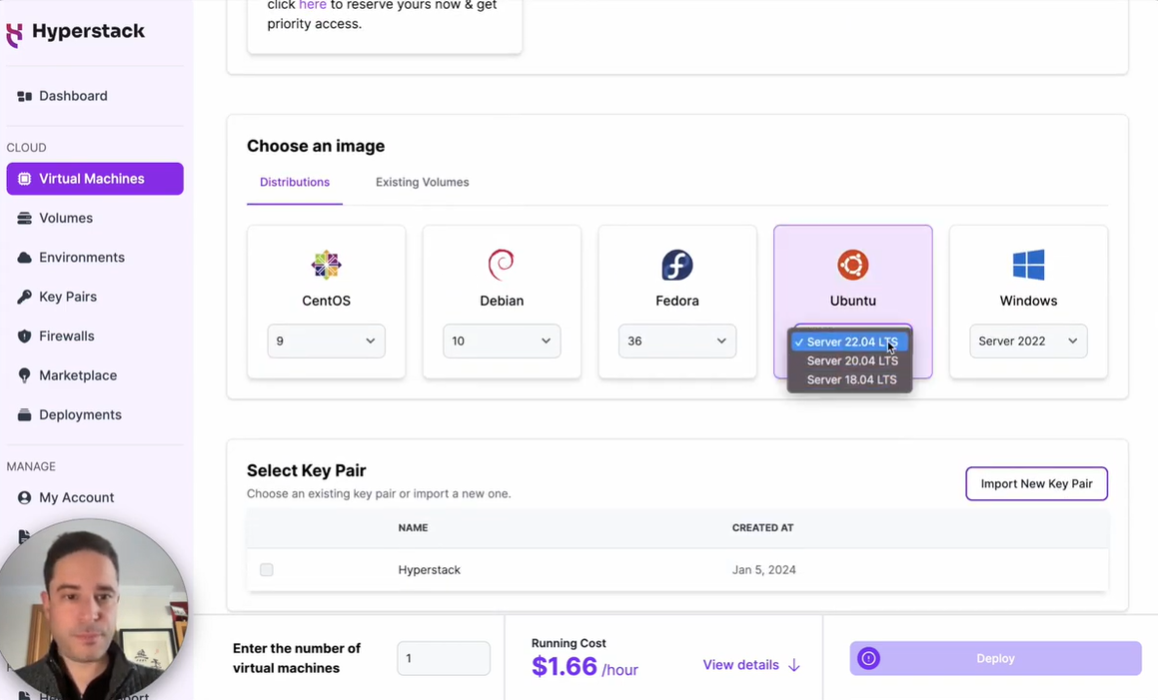
f. Pick the operating system and server accordingly (e.g., Ubuntu).
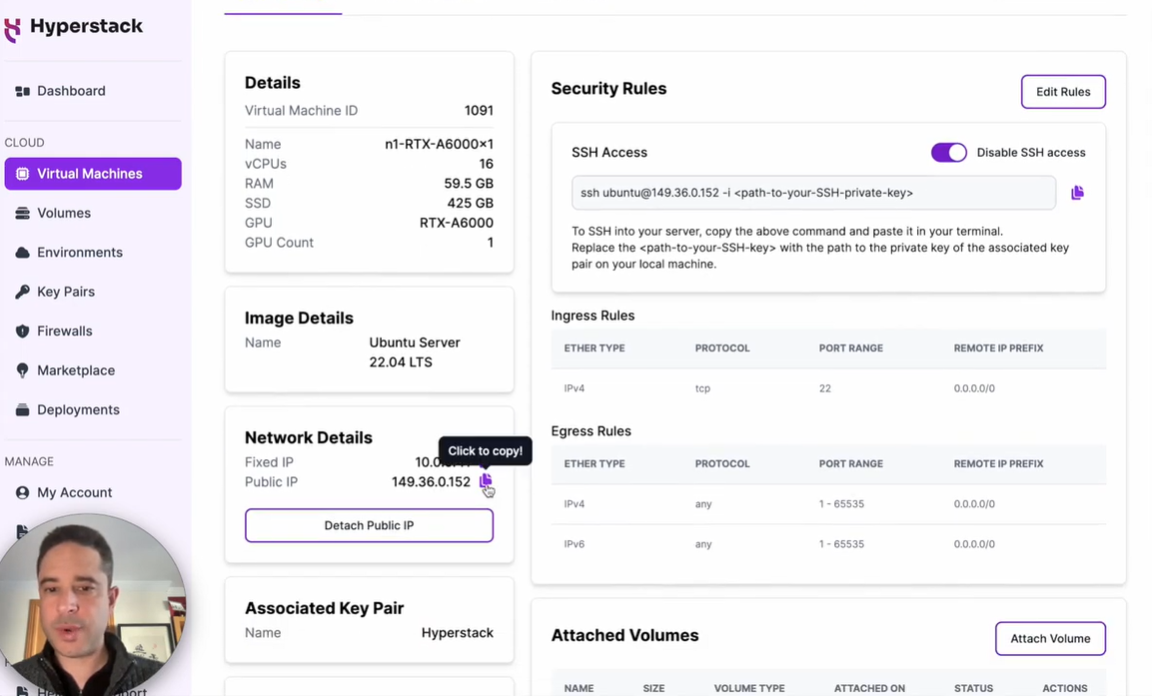
g. Set up SSH keys and ensure you have a public IP by clicking on “Assign Public IP”.

h. Enable the “Auto-install Nvidia drivers” option to add NVIDIA drivers.
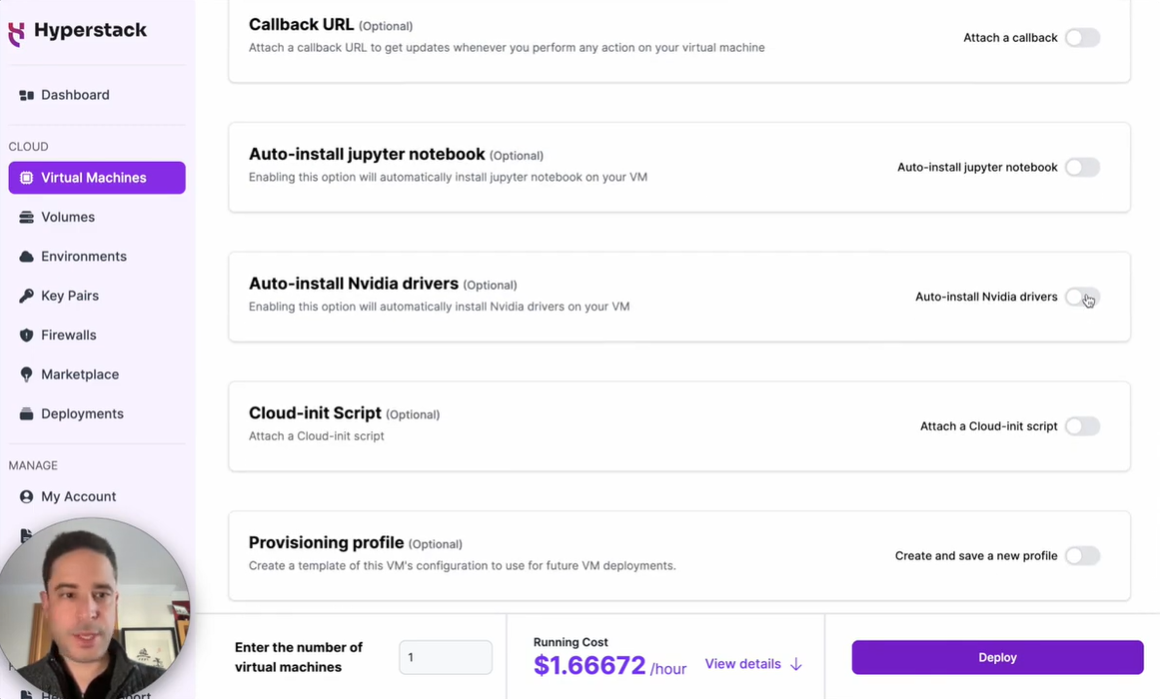
i. Click on “Deploy” to deploy the VM.

2. How to Access the VM?
Once launched, we can connect to the VM and SSH will be enabled:
a. Use the terminal to SSH into the VM using the provided public IP and Ubuntu as the username.
b. Verify the GPU (Nvidia RTX A6000) availability.

3. How to Setup Jupyter Notebook?
Next, we'll install Jupyter and set up our notebook environment:
a. Create a new directory and copy the repository URL.

b. Clone the desired GitHub repository to the VM.
c. Start with a virtual environment for dependency management.
d. Install Jupyter Notebook in the virtual environment.
4. How to Run the Code
With Jupyter installed, we can now access and run notebooks:
a. Start Jupyter Notebook with specific parameters (no browser, specific port).
b. In a new terminal, create an SSH tunnel with port binding for remote access.
c. Access the Jupyter Notebook through your local machine's browser.
d. Run the notebook step-by-step, including installing dependencies and loading the model.
e. Example code includes fetching the Kandinsky 3 model from Hugging Face Hub and deploying it to the CUDA target on the Nvidia GPU.
f. Generate images using new text inputs.
Watch the full tutorial below!
Also Read: Running a Chatbot: How-to Guide
And that's it! As you can see, Hyperstack’s ability to run unconstrained over on-demand GPUs for AI acceleration is a game changer. Within just a few clicks and a couple of commands, you can launch a notebook server equipped with a powerful GPU instance. This allows you to leverage the performance gains from GPU computing for machine learning, deep learning, and other demanding workloads.
Hyperstack takes care of all the infrastructure and configuration in the background so you can focus on being productive. So next time you need some GPU power for your Jupyter Notebook projects, remember Hyperstack is a fast, reliable and cost-effective solution. Simply launch your notebook, select your preferred GPU and start crunching!
Sign up today to access the Hyperstack Portal!
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

