.png)
TABLE OF CONTENTS

Updated: 11 Feb 2025
Oobabooga's web-based text-generation UI makes it easy for anyone to leverage the power of LLMs running on GPUs in the cloud. With a few clicks, you can spin up a playground in Hyperstack providing access to high-end NVIDIA GPUs, perfect for accelerating AI workloads. Oobabooga's intuitive interface allows you to boost your prompt engineering skills to get the most out of open-source models like Mixtral-8x7B, Llama 2-70B, and more. In this tutorial, we'll provide an Oobabooga tutorial on how to use the Oobabooga Web UI to fully utilise the power of LLMs on Hyperstack for whatever creative or productive purpose you may have. Let’s get started!
Similar Read: How to Run Jupyter Notebooks Like a Pro on Hyperstack
Use Case
The use case for this tutorial is to summarise a YouTube video by Ilya Sutskever, OpenAI Chief Scientist for sharing key insights with a community to spark discussion. The goal is to summarise the video transcript which explores the intriguing concept that next token prediction in AI models could potentially surpass human performance in generating thoughtful responses. So, we are considering potential model options like the Mixtral-8x7B and Llama 2-70B leveraging via the Oobabooga Web UI. The interface makes it easy to experiment with different models and prompt engineering.
Similar Read: Tips and Tricks for Developers of AI Applications in the Cloud
Step 1: Understanding Memory Requirements
One common question is how much GPU power is required to run these large models. Resources like Eleuther.ai GPU memory requirement listings help provide estimates for planning purposes when working with different-scale LLMs.
So for floating point 16 and Bf 16, this is the formula:
2 bytes per param x number of params x 1.2 (for 20% extra memory needed for forward pass during inference)
The larger one is Llama 2 with 70 billion parameters. Now, let's do some quick math:
2 x 70 billion params x 1.2 = 168 GB
Step 2: Finding the Right GPU
As we look into fitting these large language models, leveraging GPU acceleration is key. The first step is to choose the right GPU. The NVIDIA L40 with its 48GB of graphics memory per card seems a versatile fit - ideal for both graphics and AI inferencing workloads we aim to run in our playground.
While the NVIDIA H100s or A100s may be better suited for larger-scale model training, the NVIDIA L40 hits the sweet spot when we just want to try out models and generate text. And with 48 gigs per card, we're hoping it has enough muscle to run models like the Llama 2-70B.
So how many GPUs will we need to fit this beast? For this, we need to come back to our calculations:
Divide 168 by 48 = 3.5
So in this case, we will round up to 4 cards i.e. 4 NVIDIA L40 GPUs.
Step 3: Deploying Your VM on Hyperstack
Now that we are aware of the GPU memory requirements to run large language models like Llama 2-70B, let's start deploying a Virtual Machine instance on Hyperstack that meets these needs.
a. Go to Hyperstack Dashboard: Log in and head to the VM deployment section. Click on “Deploy New Virtual Machine”.
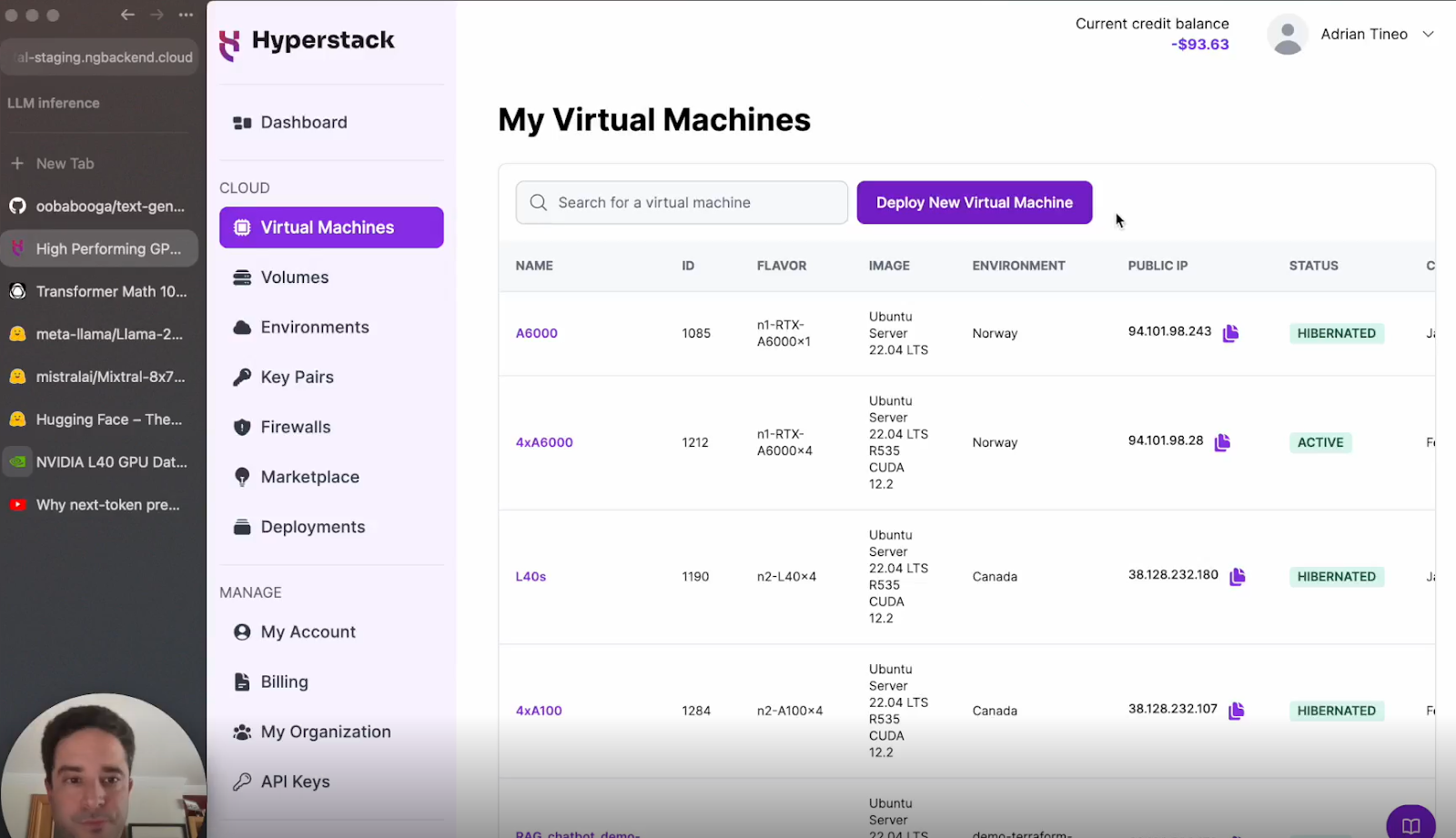
b. Create a New VM: Name it "LLM Inference".

c. Select Environment: Locate the desired node flavor in your region of choice.

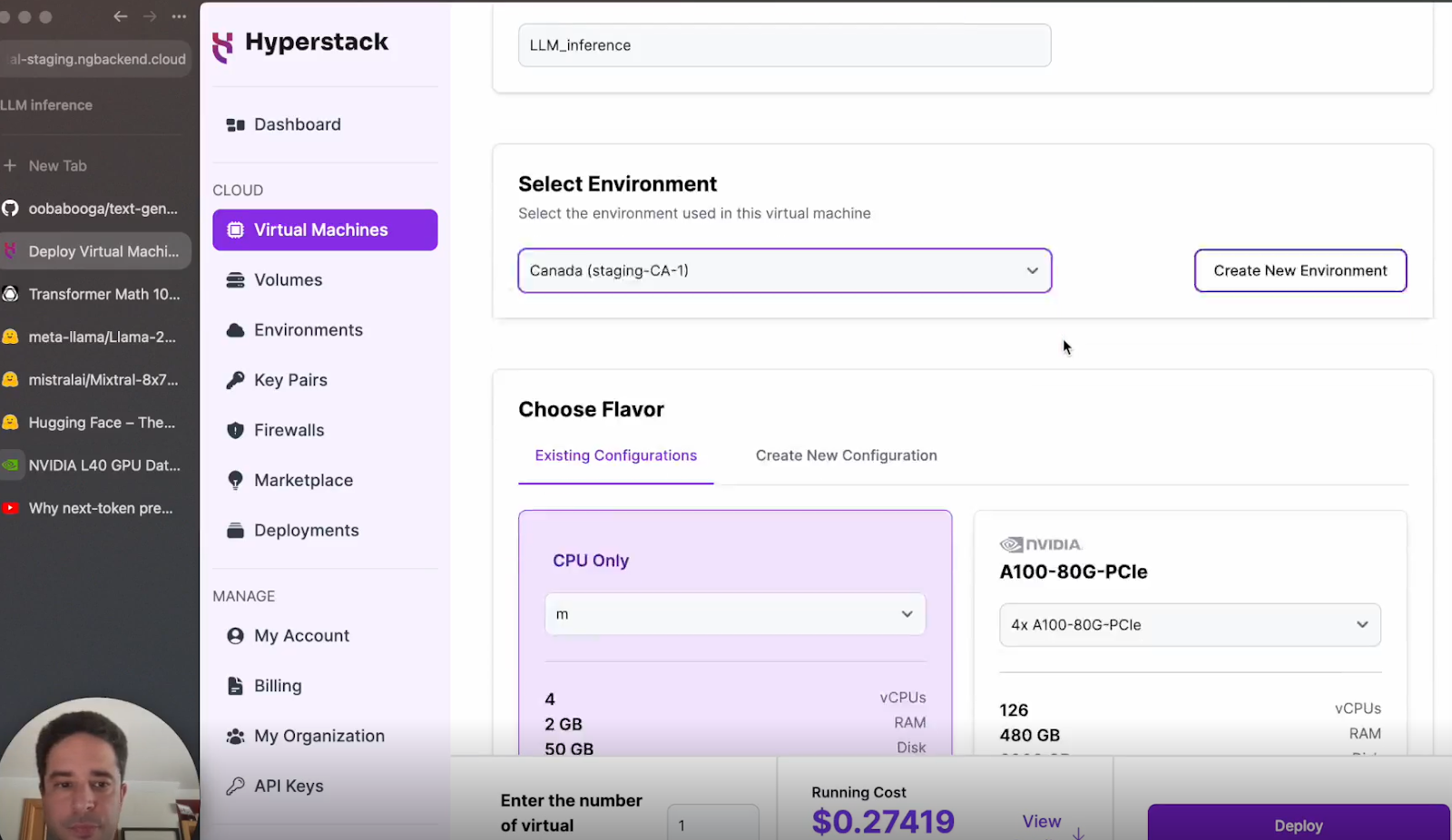
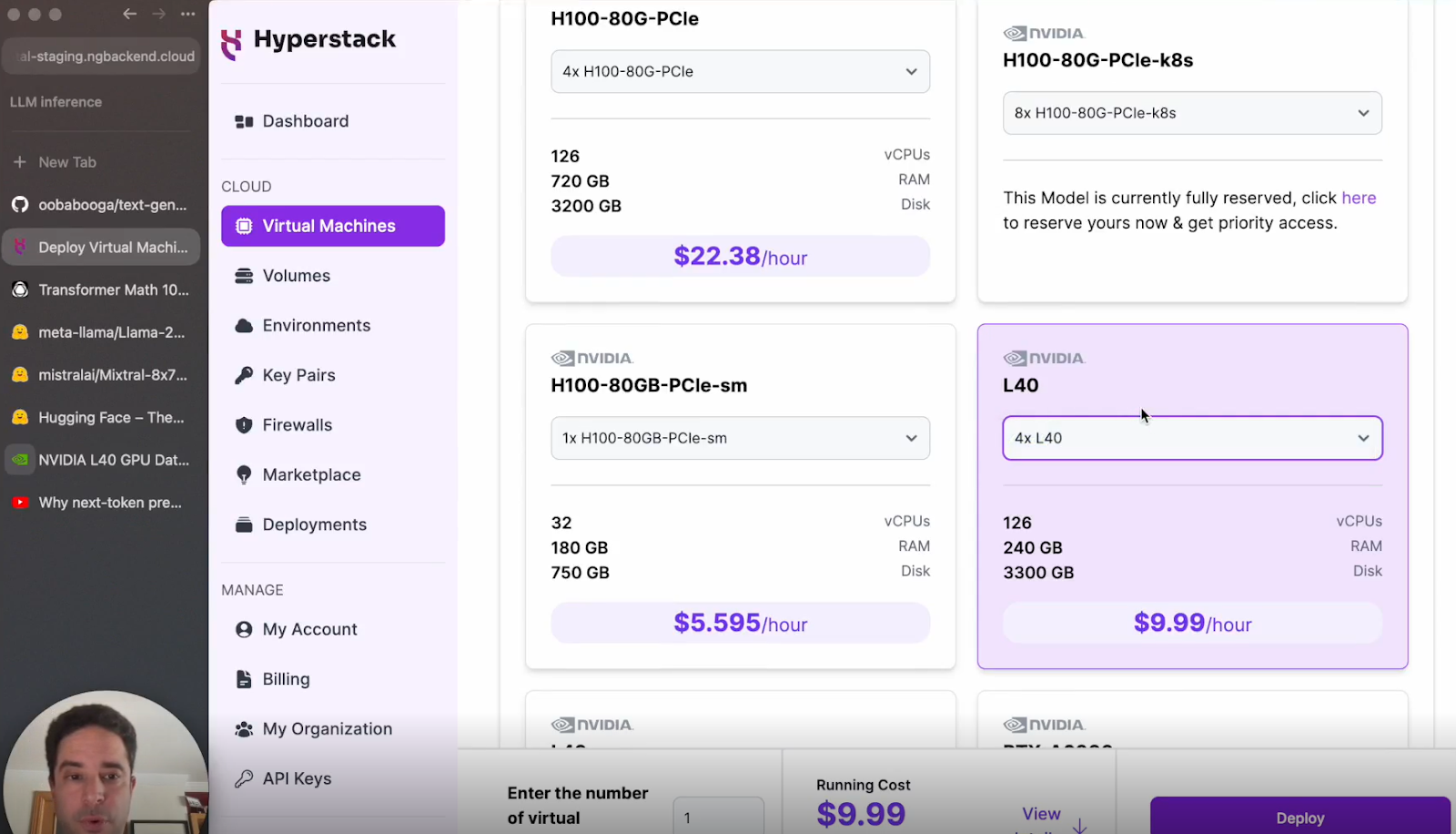
d. Select the configuration: Click on the L40 GPU configuration.
e. Choose an operating system: Opt for Ubuntu as your operating system and ensure you have a public IP address.
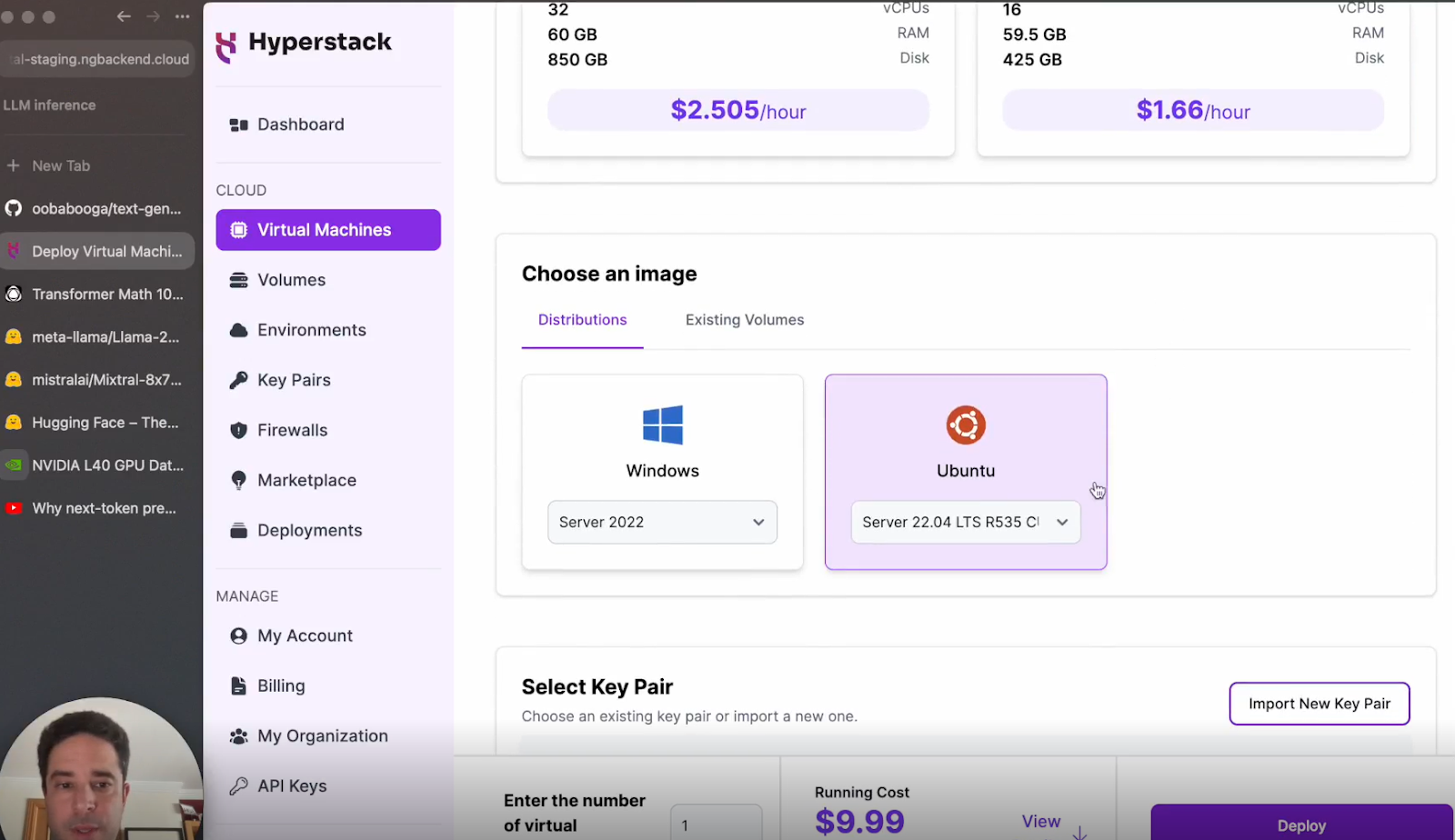
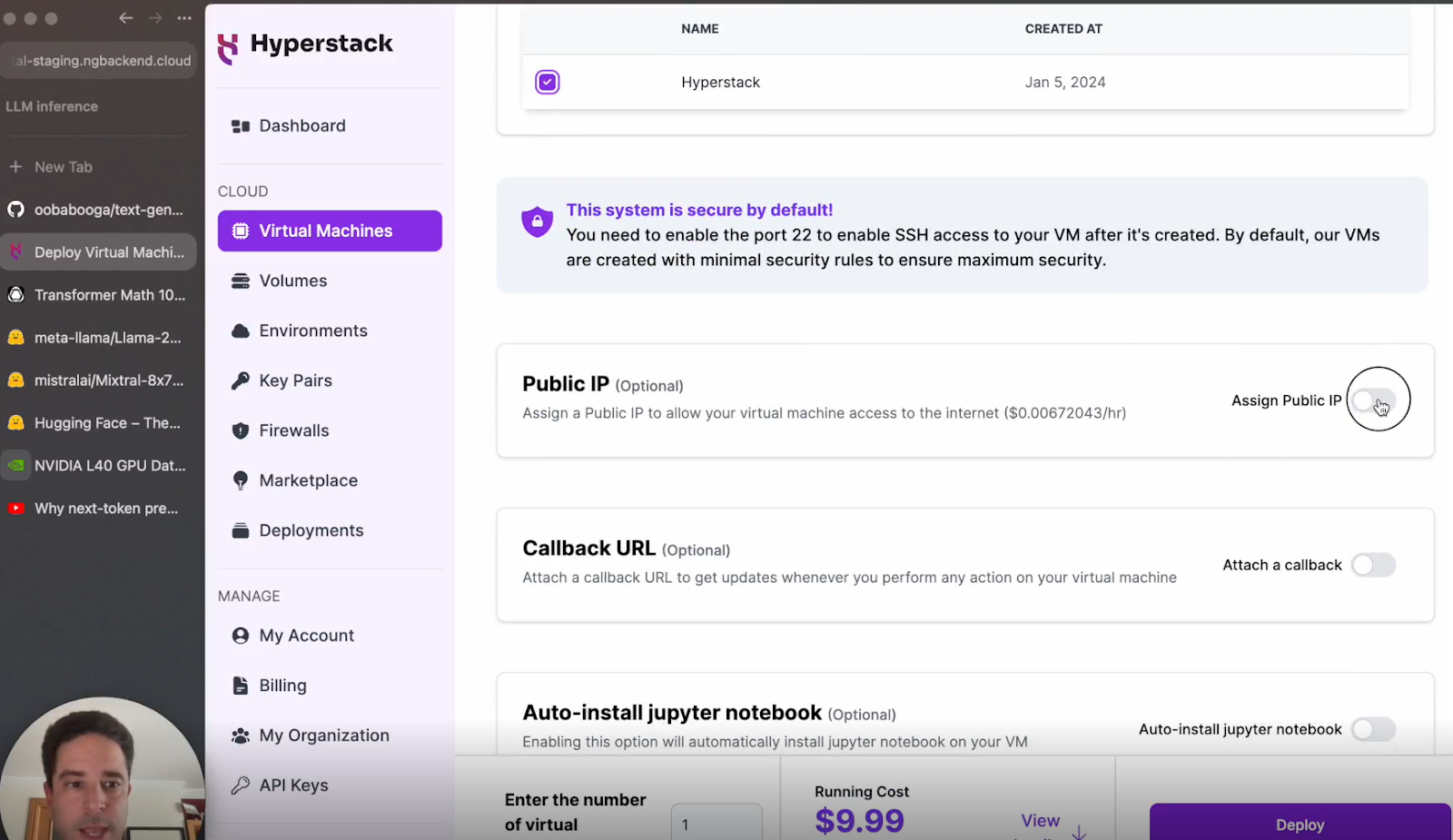
f. Deploy: Click deploy and wait for the VM to be ready.
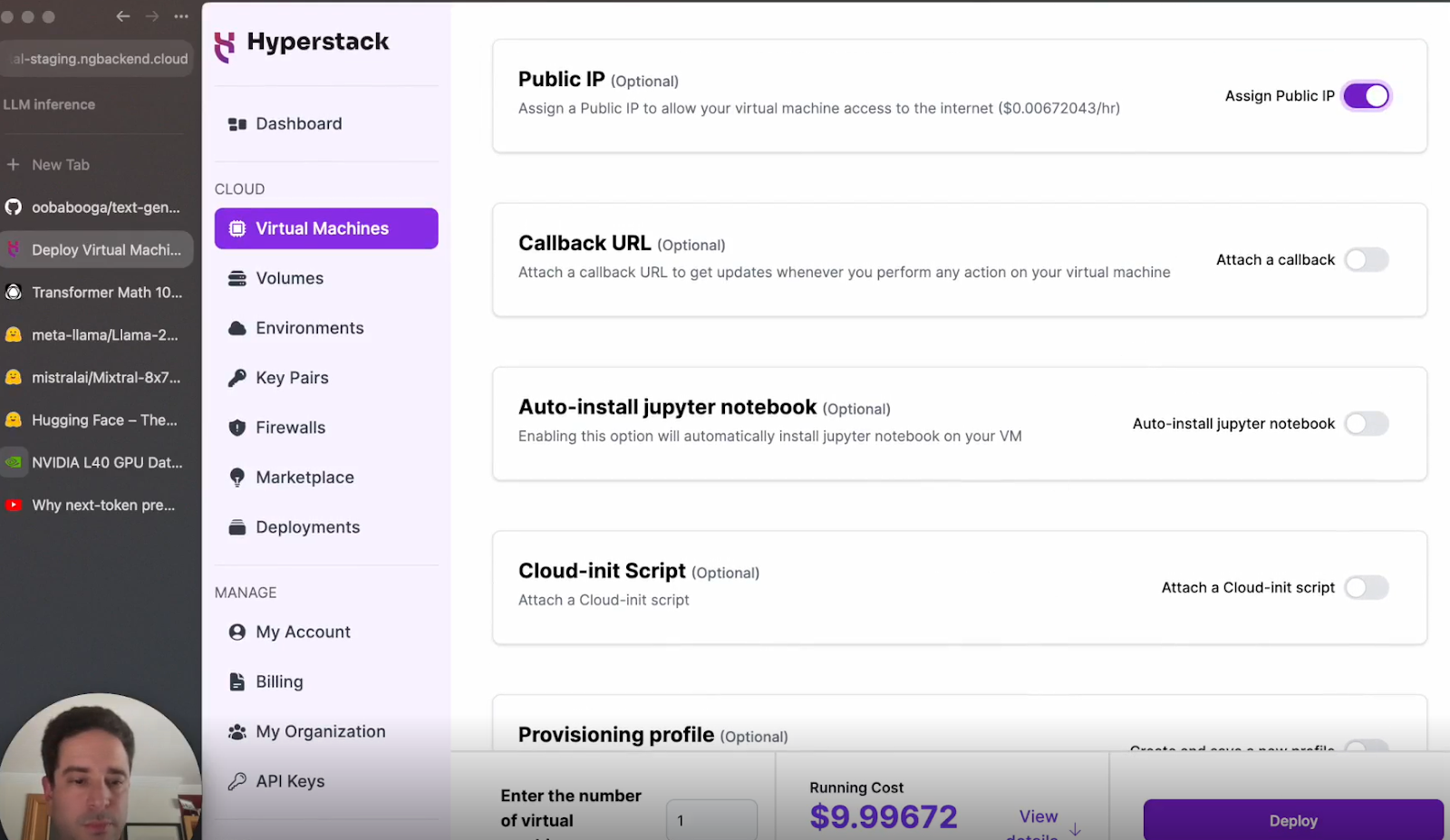
Step 3: Setting Up Your Environment
Once your VM is deployed:
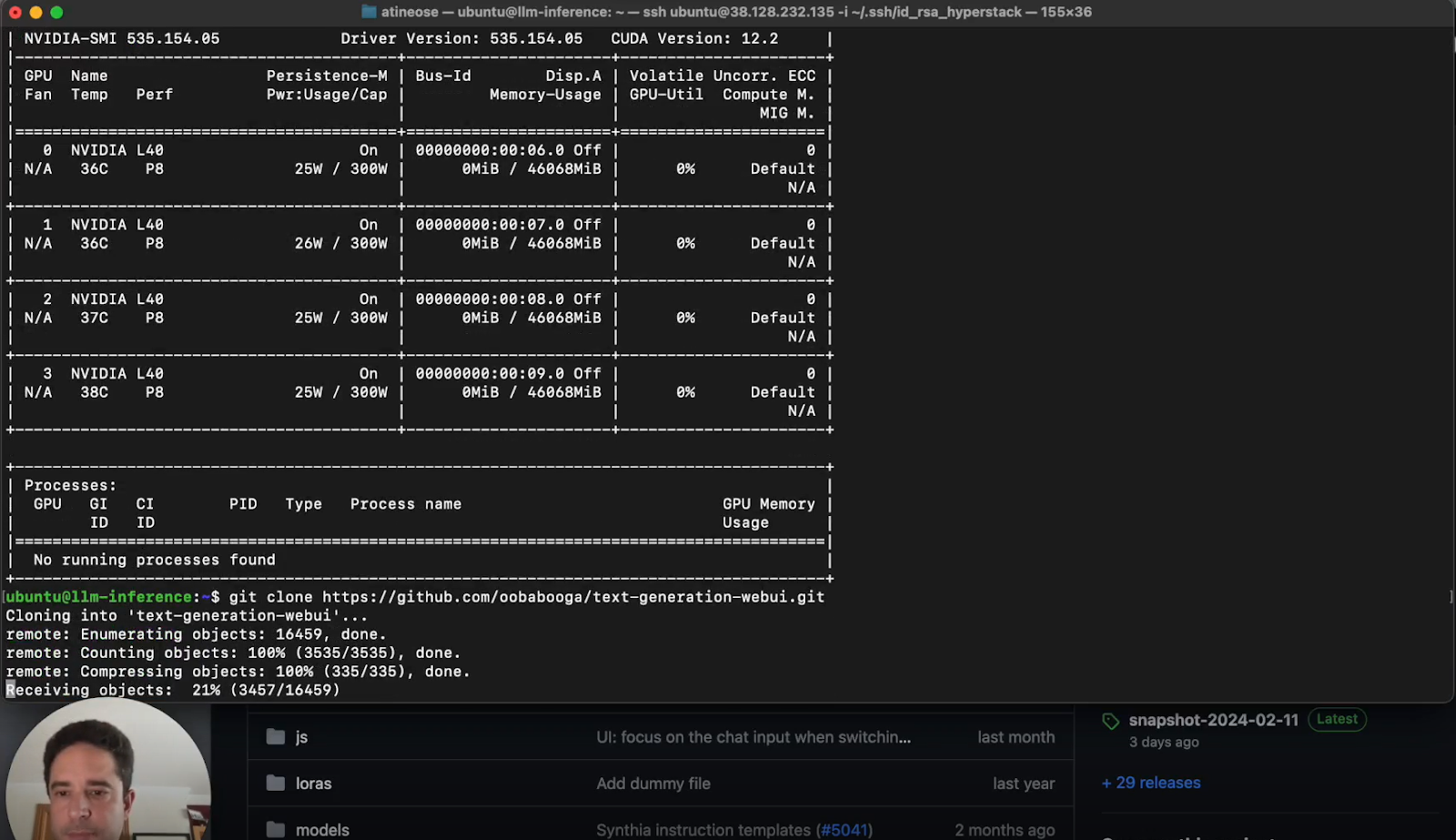
a. SSH into Your VM: Use the provided IP address and enable your SSH key.
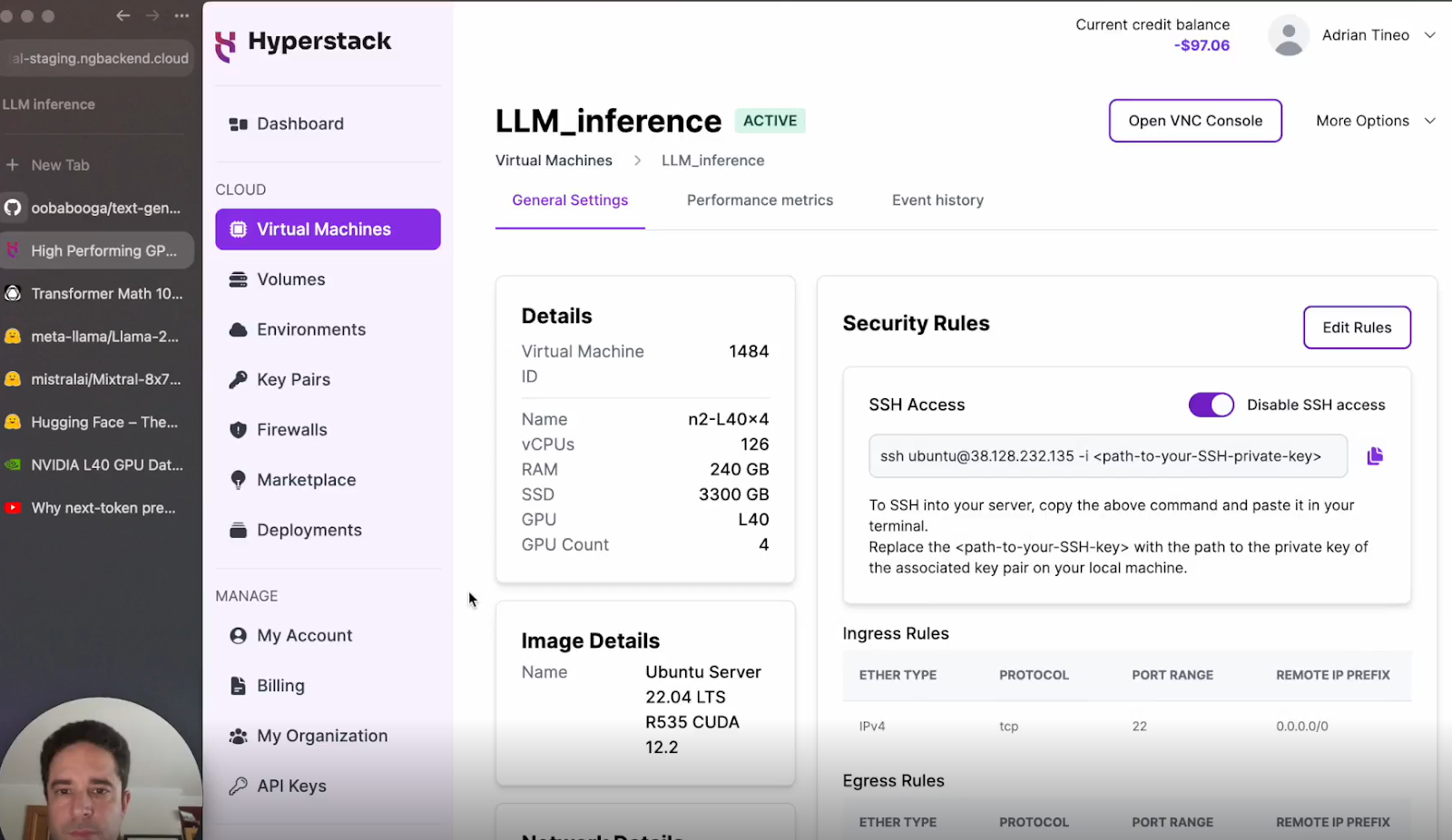
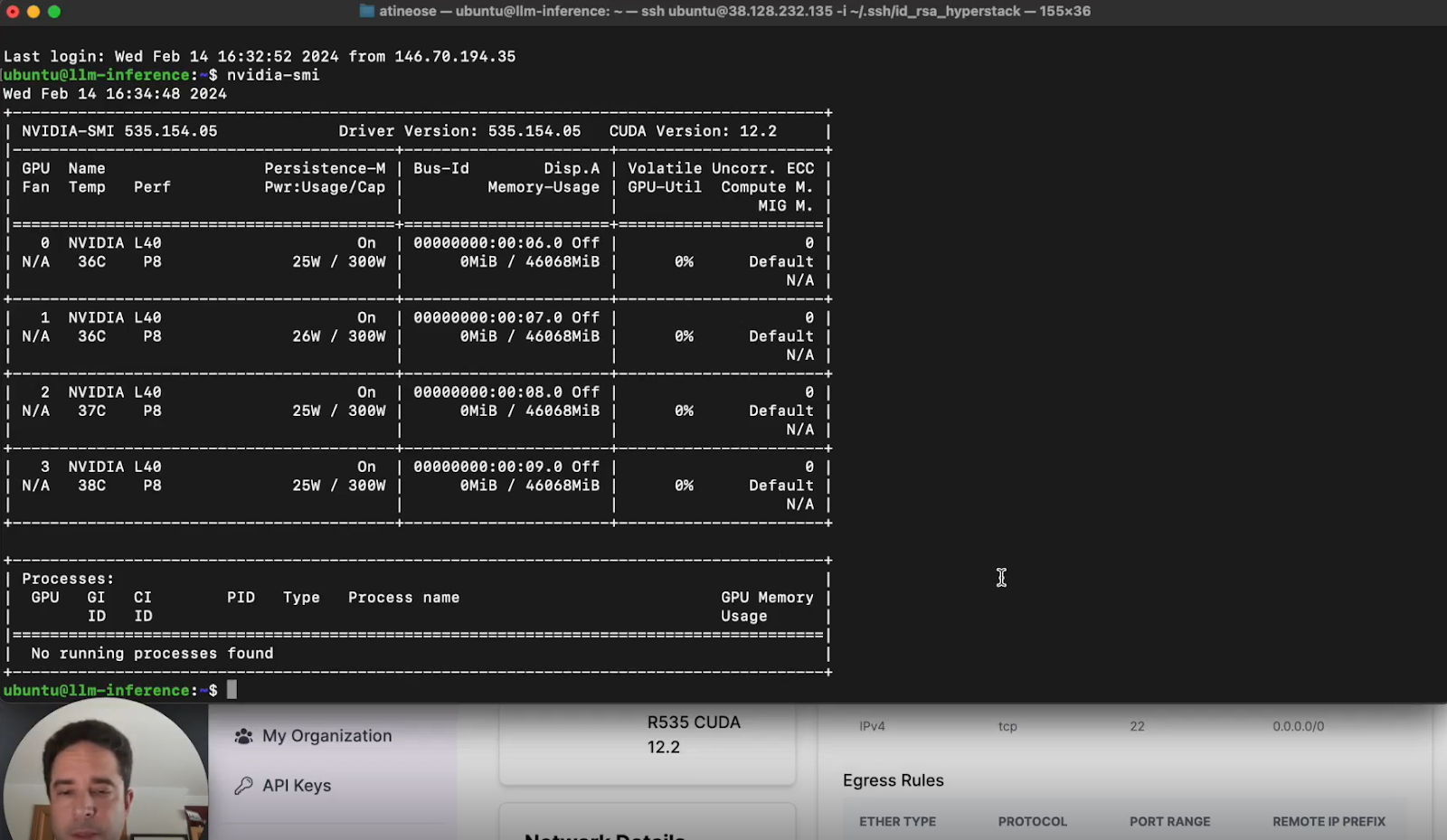
b. Verify GPU Allocation: Use commands like nvidia-smi to ensure the GPUs are correctly allocated.
c. Copy the repo URL: Copy the Oobabooga Text Generation Web UI from its repository and clone it.
Step 4: Starting the Web UI
Now that we have cloned the repo, we are ready to get started with UI to test large language models.
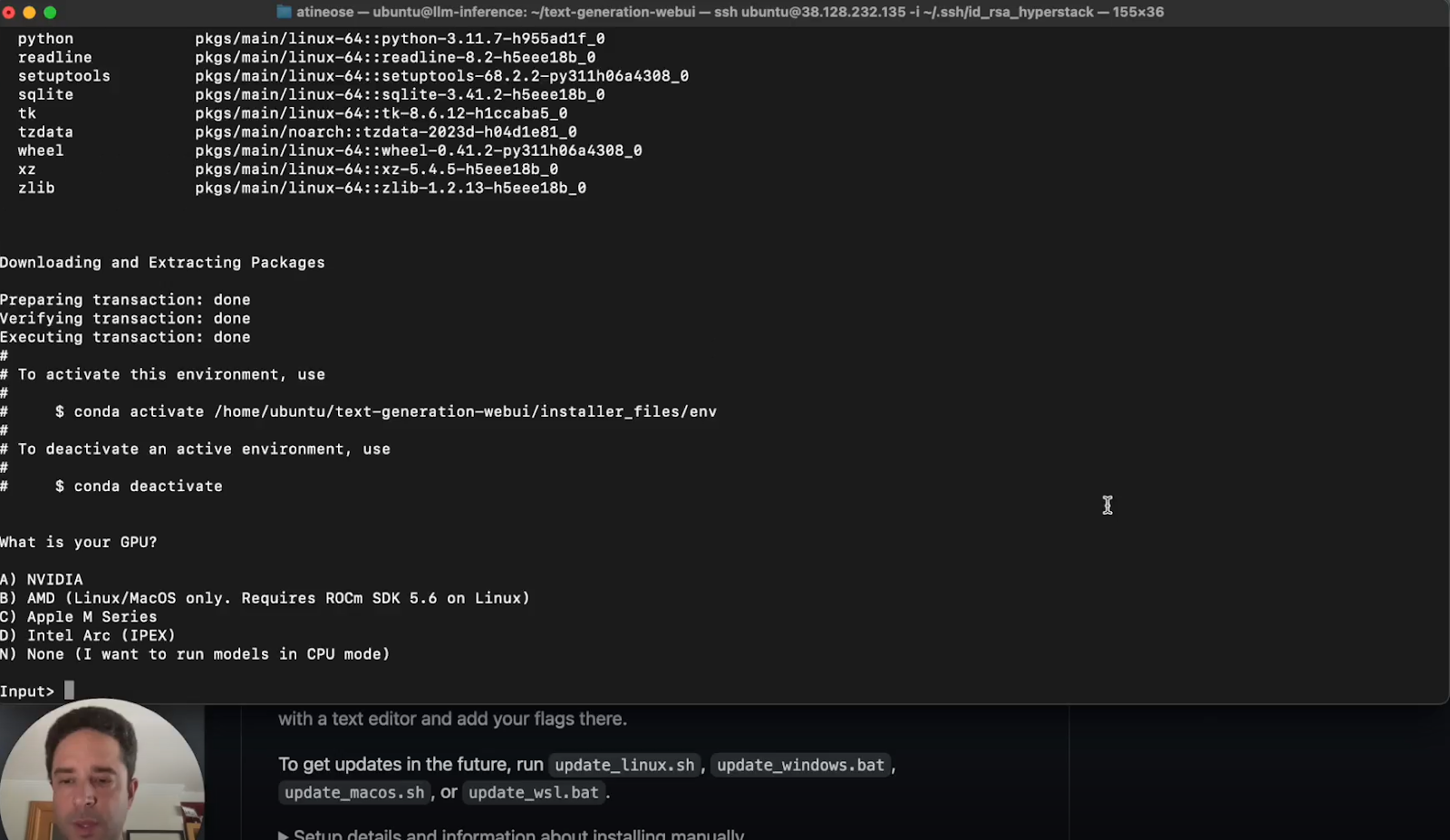
a. Install Dependencies: Follow the README in the Oobabooga repository to install necessary dependencies, particularly focusing on Linux commands if your VM is Ubuntu-based.

b. Configure GPU Memory: Use “share—gpu-memory” to specify memory allocation per GPU.The key here is to give as many numbers as the GPU you plan to use. The number is the upper bound of memory that will be allocated per card.
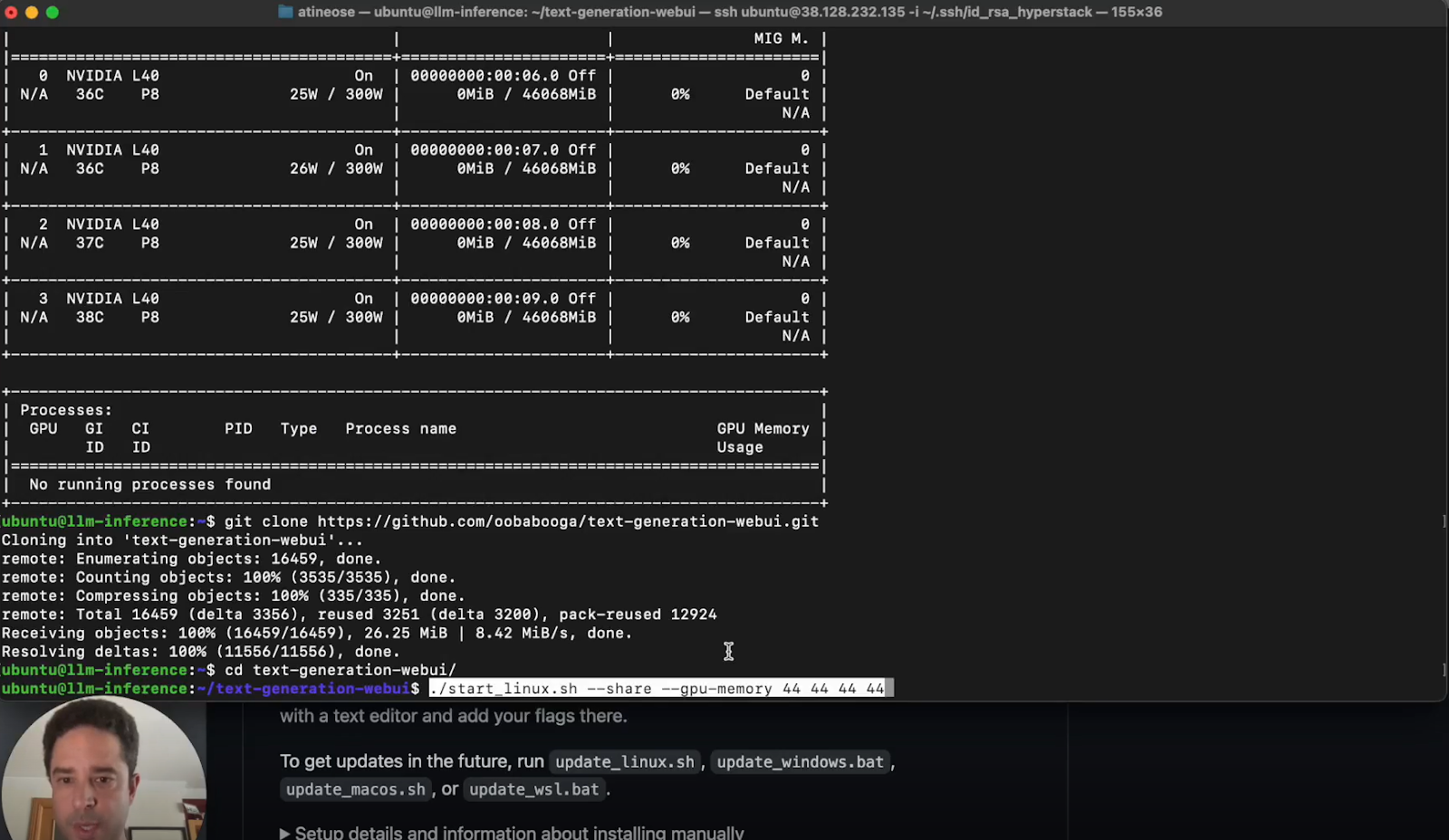
c. Launch the Web UI: Execute the launch command, adjusting parameters for your Linux environment and GPU configuration.
d. Copy the URL: Click on the public URL and copy it.
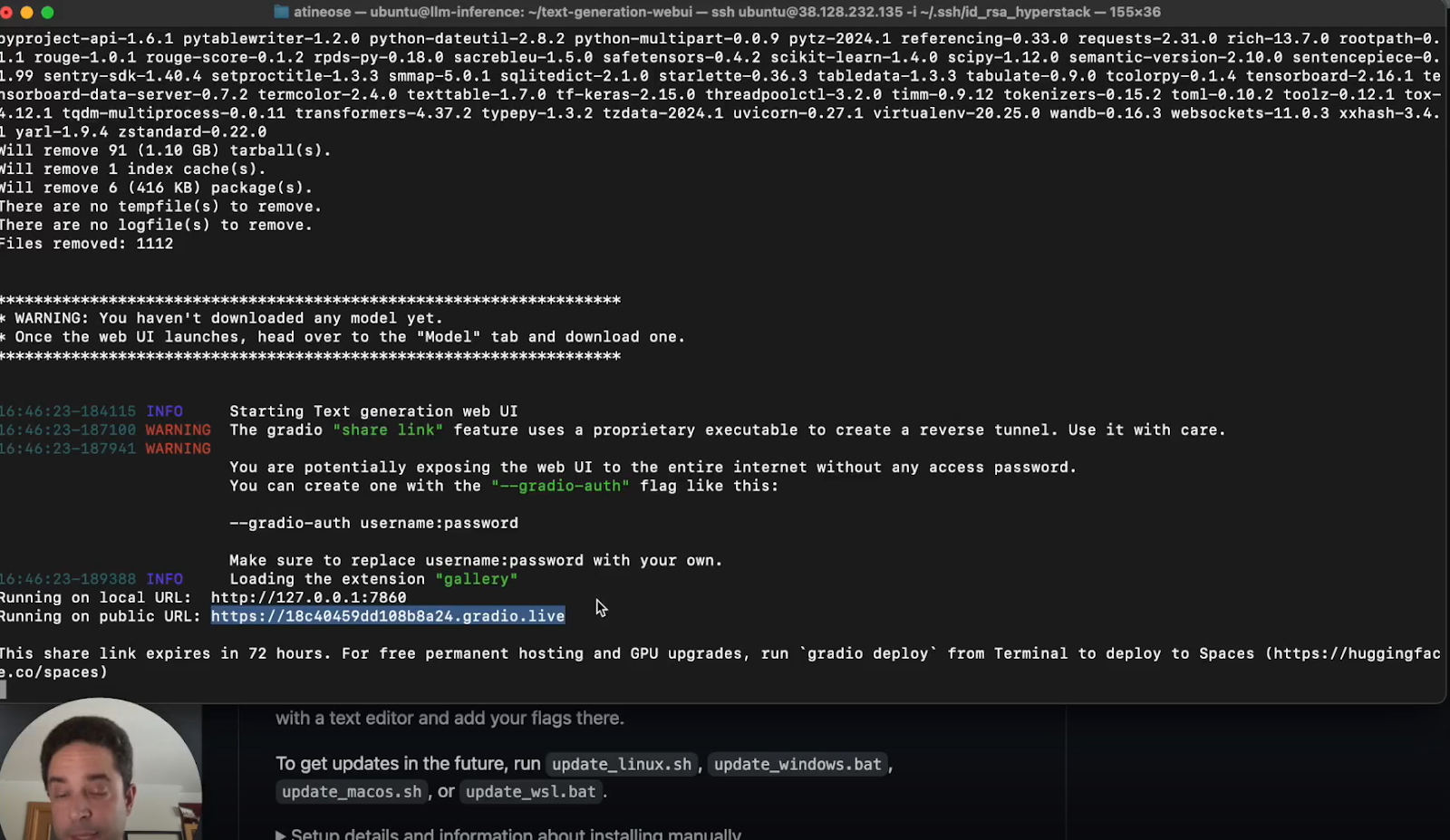
e. Enter the URL: Go to the browser and enter the copied URL.
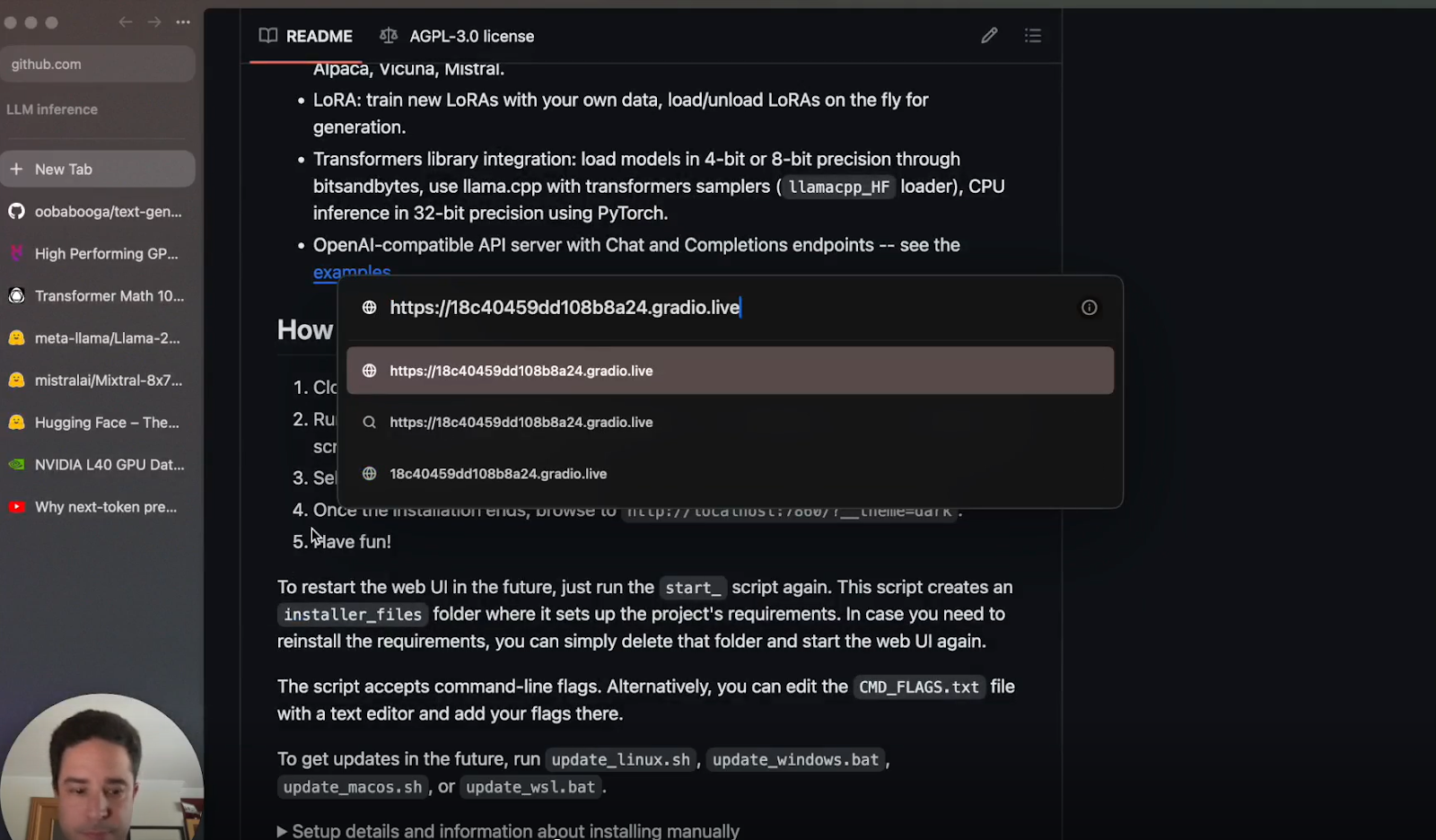
Step 5: Downloading and Running Models
After entering the URL, you will be directed to the Web UI. Now, you will need to download the models to start interacting with the Web UI:
a. Download Models: Use Hugging Face to download the Mixtral-8x7B and Llama 2-70B models.
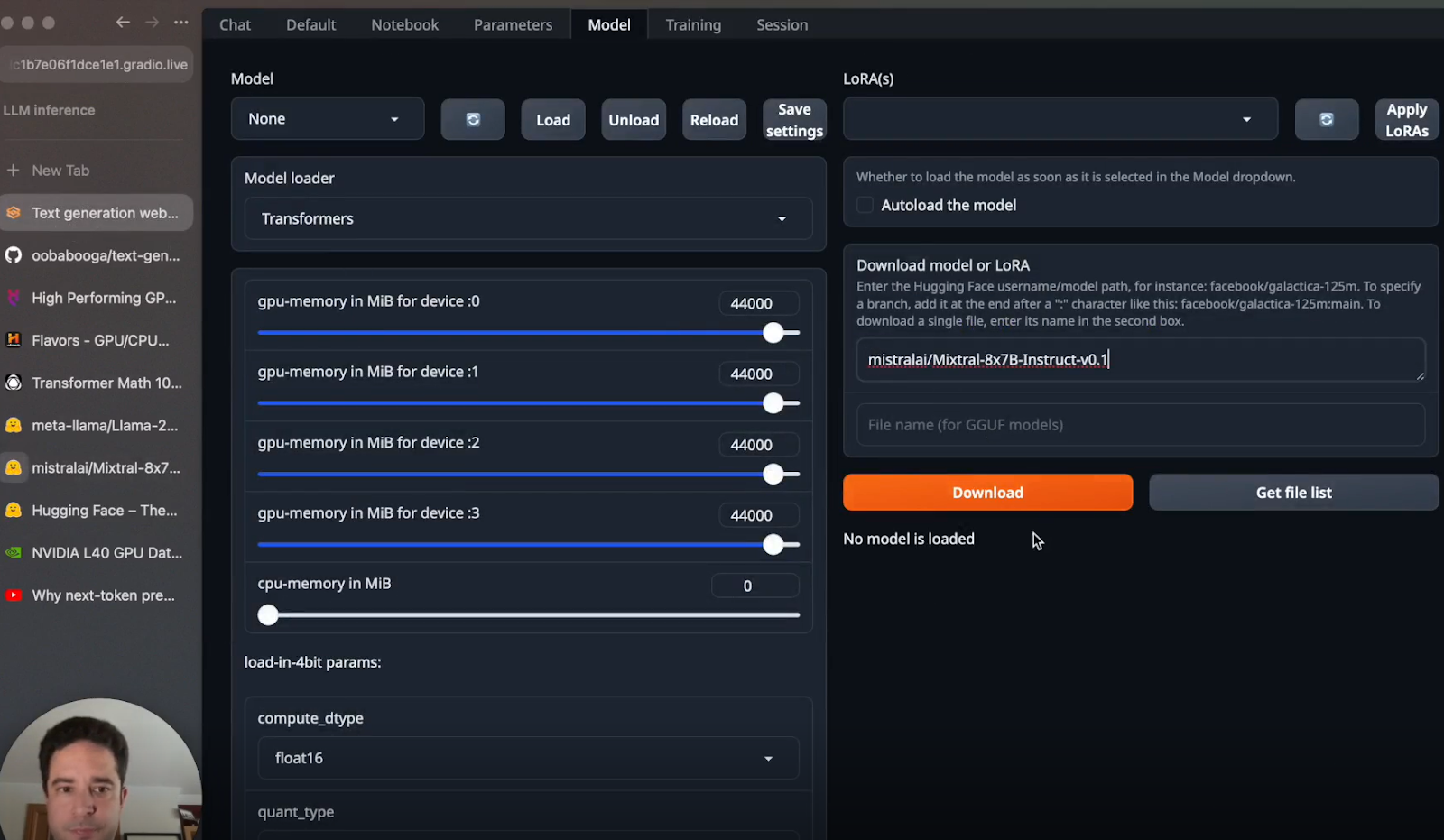
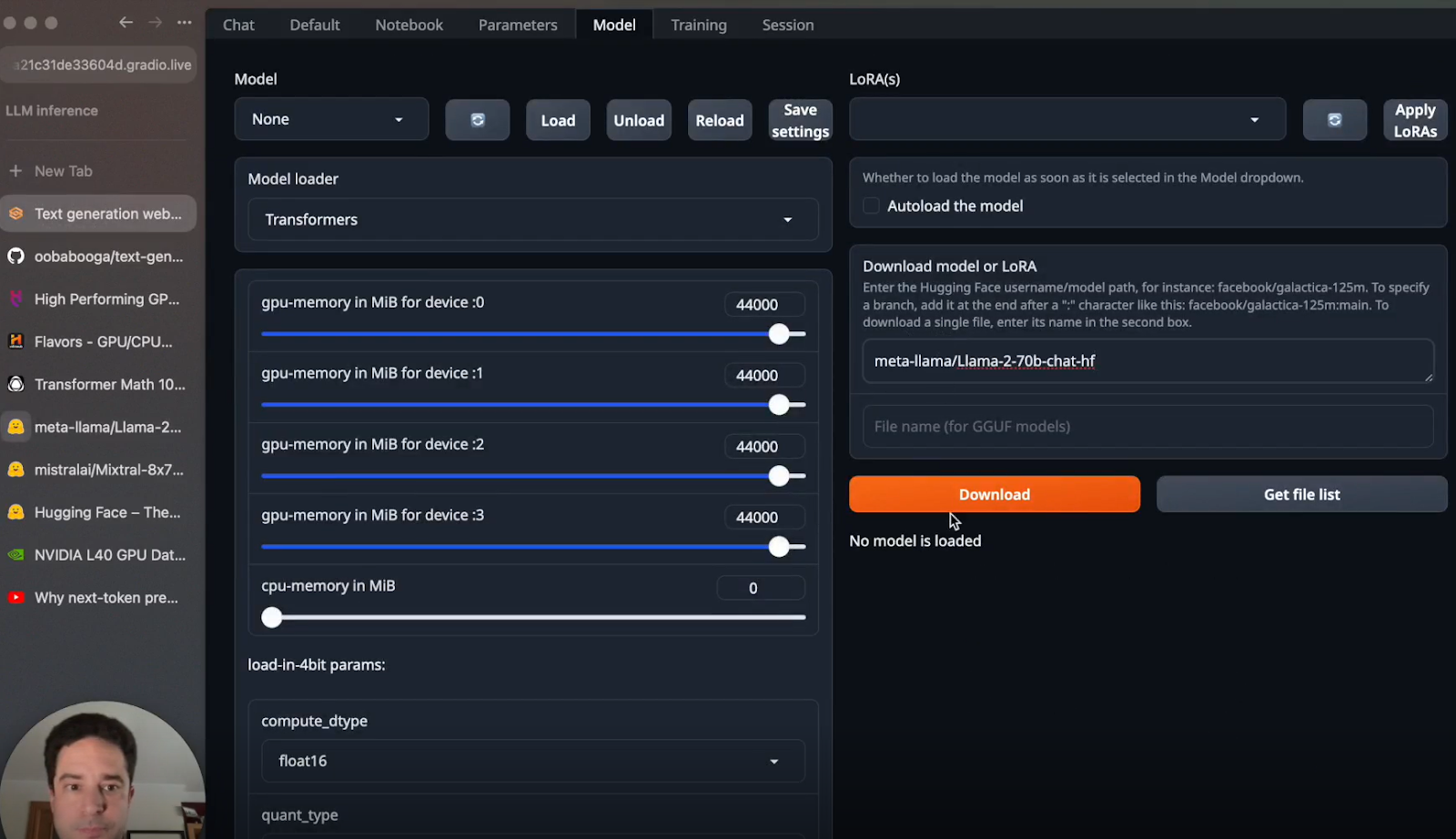
b. Load Models into the Web UI: After downloading, load your chosen model through the Web UI interface.

c. Input Your Transcript: Paste the transcript you wish to summarise in the chat interface.
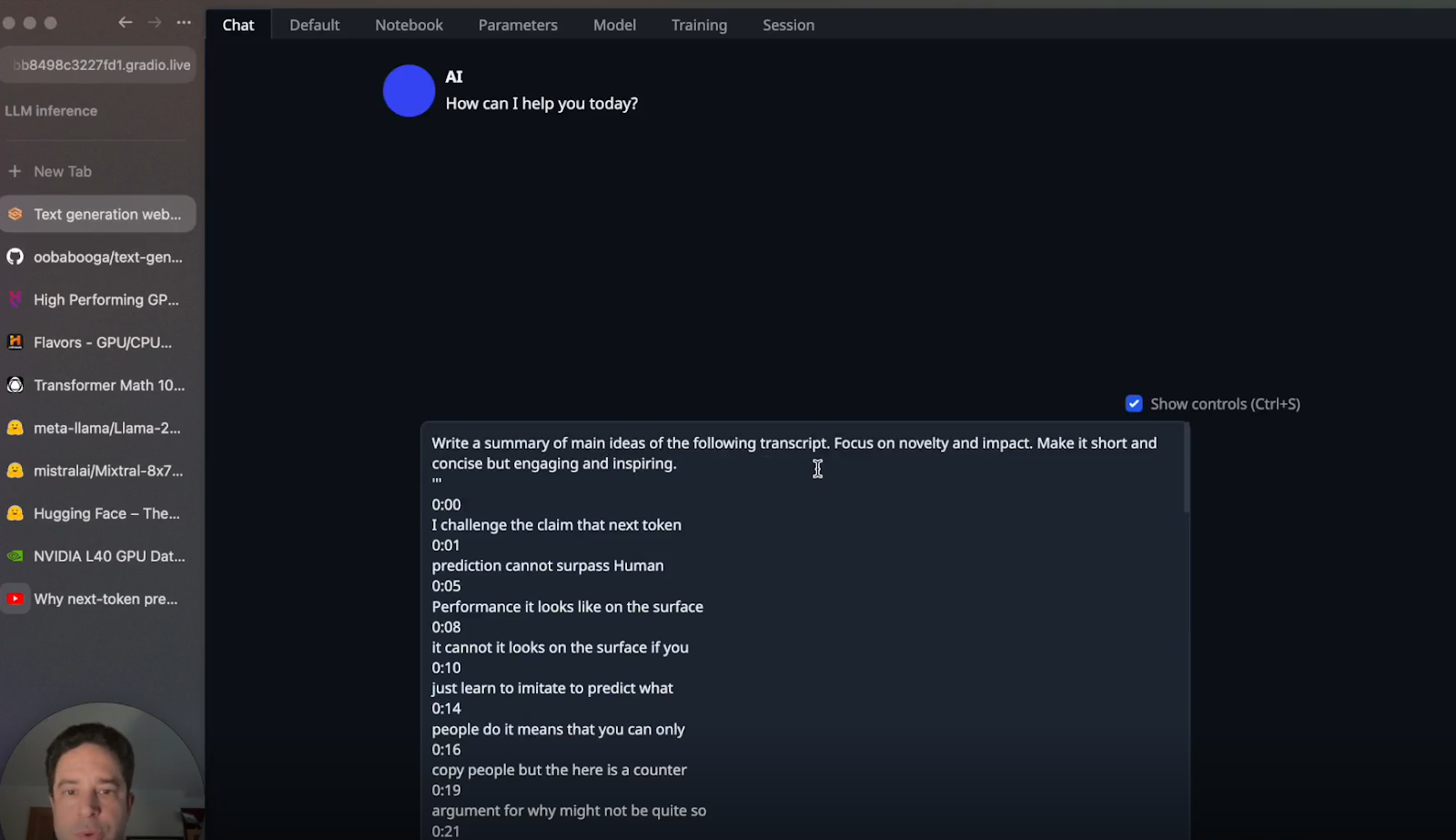
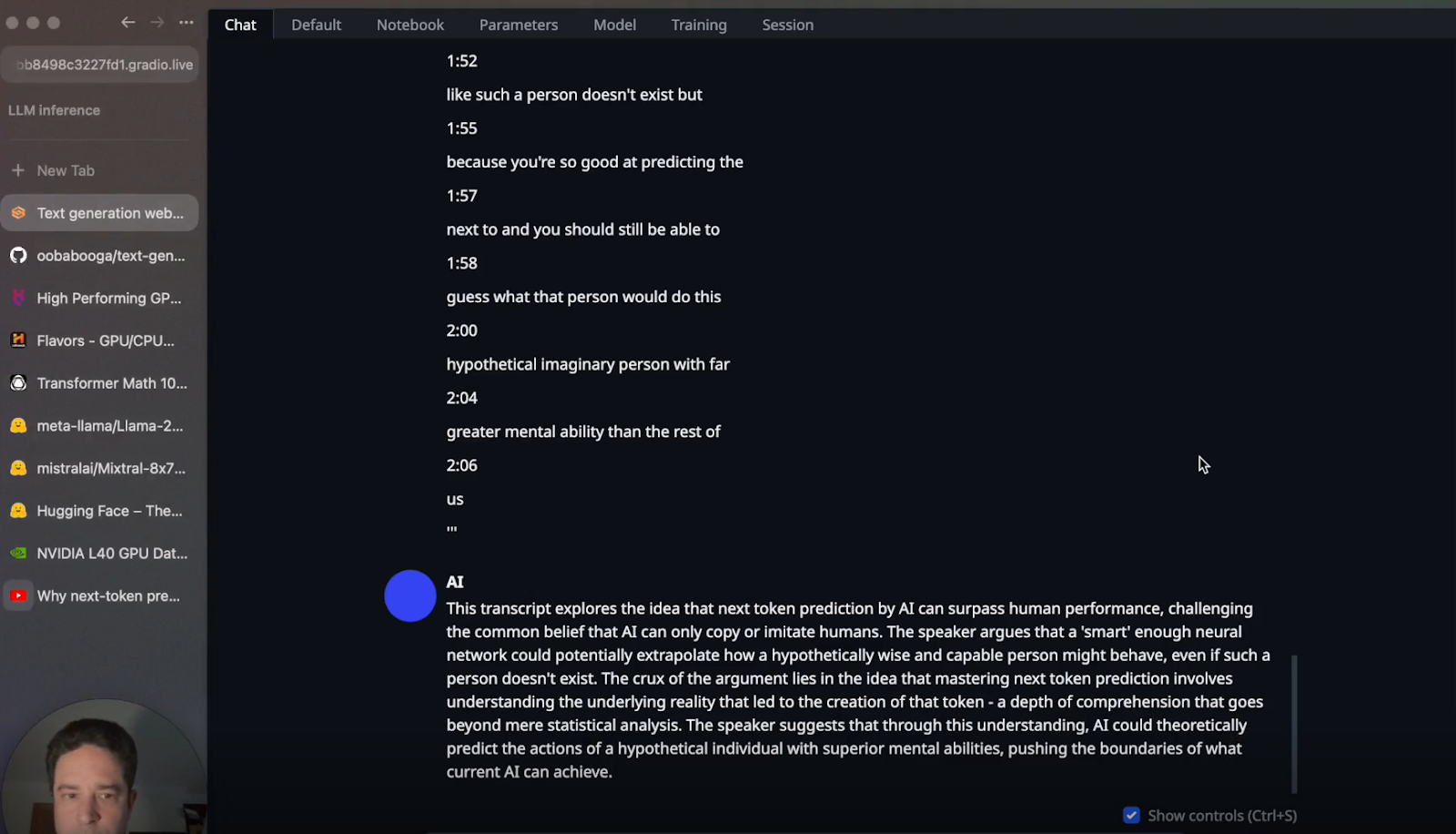
d. Generate Summary: Prompt the model for a summary and review the output from both models
For Llama 2-70B:

For Mixtral-8x7B:
Similar Read: How to Train Generative AI for 3D Models
Step 6: Evaluating Outputs
Now, you can compare the summaries generated by both models. You can utilise the Web UI to fine-tune responses, adjusting parameters like temperature to vary output creativity.
Conclusion
Congratulations! You've successfully used the Oobabooga Web UI on Hyperstack to interact with LLMs. You can experiment with different models and settings to explore the vast capabilities of your pace.
Watch the full tutorial below
Stay tuned for the next part of this series where we will learn about the comparisons of Mixtral-8x7B and Llama 2-70B, different use cases and a deeper speed of inference profile.
Sign up today to access the Hyperstack Portal and experience the power of high-end NVIDIA GPUs for LLMs!
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 11 Apr 2025
11 Apr 2025