.png)
TABLE OF CONTENTS

Updated: 11 Feb 2025
NVIDIA H100 SXM On-Demand
Technology has never been more intimately connected to the human experience than through the concept of neural networks in machine learning. Neural networks are sophisticated computational models that draw inspiration from the biological neural networks found in the human brain. These intricate systems are designed to mimic the way neurons in our brains process information and help them learn from vast amounts of data and recognise complex patterns.
Neural Networks in Machine Learning have proven remarkably successful in various domains, including image and speech recognition, natural language processing, and even gaming. According to a study by Stanford researchers, neural networks could accurately determine a person's sexual orientation from facial images with startling accuracy - 81% for men and 74% for women from a single image, outperforming the human perception which was 61% for men and 54% for women. This shows how far technology like neural networks has come - it's fascinating to see artificial systems outperforming humans at such a nuanced perception task by detecting subtle patterns invisible to the naked eye.
History of Neural Networks
The history of neural networks dates back to the 1940s when neurophysiologist Warren McCulloch and mathematician Walter Pitts modelled a simple neural network using electrical circuits to describe how neurons in the brain might work. In 1949, Donald Hebb's work on neural pathways strengthening with use laid the foundation for human learning processes. The 1950s saw advancements in neural networks, with John von Neumann's theory making work on neural networks probable due to his innovation by proposing a hypothetical self-reproducing automaton that followed a specific set of rules consisting of computational elements, manipulating elements, cutting elements, fusing elements, sensing elements and information storage elements that also served as structural elements.
In the late 1950s, Frank Rosenblatt developed the perceptron, an algorithm for pattern recognition, marking a significant milestone in artificial neural networks. The field faced challenges in the late 1960s when Marvin Minsky and Seymour Papert's book "Perceptrons" highlighted the limitations of single-layer perceptrons, leading to a decline in neural network research until the 1980s. The resurgence of neural networks in the 1980s was fueled by advances in algorithms like backpropagation and recurrent neural networks, along with increased processing power from graphics chips.
By the 1990s, neural networks had regained popularity and started to fulfil their potential, catching the imagination of researchers and the public alike. The deep learning revolution brought about by advancements like backpropagation and GPU technology propelled neural networks back into the spotlight, leading to their widespread adoption in various fields.
How Neural Networks in Machine Learning Work
Neural Networks operate on a few fundamental principles. They consist of interconnected nodes or artificial neurons, organised into layers that hierarchically process information. The layers include:
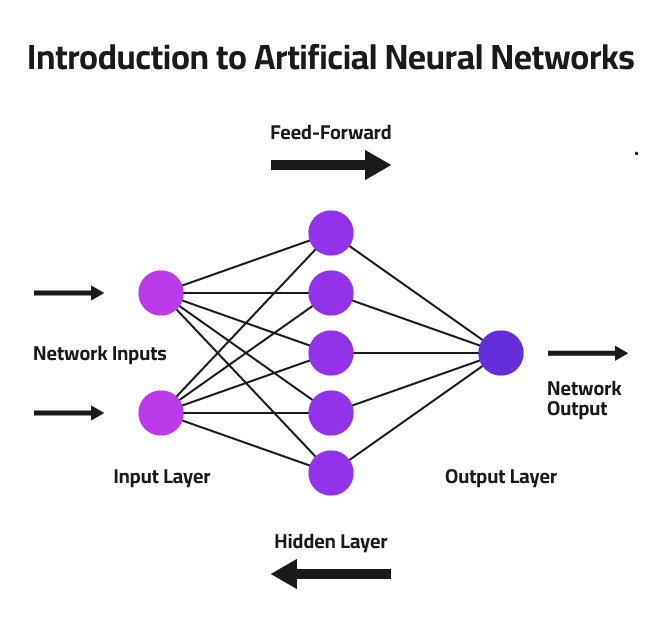
Input Layer
The first layer of a neural network is the input layer, which receives the raw data or input signals. This data can be in various forms, such as images, text, or numerical values, depending on the problem at hand. Each node in the input layer represents a single feature or dimension of the input data.
The input layer is connected to one or more hidden layers, which are responsible for performing computations on the input data. Each node in a hidden layer is connected to the nodes in the previous layer through weighted connections. These connections represent the strength or importance of the connection between two nodes, and they are adjusted during the training process.
Hidden Layer
The hidden layers are where the real magic of neural networks happens. Each node in a hidden layer receives a weighted sum of the outputs from the previous layer and applies an activation function to introduce non-linearity. This non-linearity allows neural networks to model complex relationships and patterns within the data.
Output Layer
The output from the final hidden layer is then passed to the output layer, where the network produces its prediction or classification result. The number of nodes in the output layer depends on the specific problem being addressed, such as the number of classes in a classification task or the range of values in a regression problem.
Training and Optimisation
Training and optimising neural networks enable them to learn from data and improve their performance for specific tasks. The two main techniques used for training and optimising neural networks are backpropagation and gradient descent.
Backpropagation
Backpropagation is a supervised machine learning algorithm that is used to train artificial neural networks. It is responsible for adjusting the weights and biases of the network to minimise the error between the predicted output and the desired output.
The backpropagation algorithm works as follows:
- Forward Propagation: The input data is fed through the neural network, and the output is computed using the current weights and biases.
- Error Computation: The error between the predicted output and the desired output is calculated using a loss function, such as mean squared error or cross-entropy loss.
- Backward Propagation: The error is then propagated backwards through the network, starting from the output layer. The gradients of the error concerning the weights and biases are computed using the chain rule of calculus.
- Weight Update: The weights and biases are updated using an optimisation algorithm, such as gradient descent, to minimise the error. The updated weights and biases are then used in the next iteration of forward propagation.
Similar Read: How to Use Batching for Efficient GPU Utilisation
Gradient Descent
Gradient descent is an optimisation algorithm used in conjunction with backpropagation to update the weights and biases of the neural network. It is a method for minimising a function by iteratively adjusting its parameters in the direction of the negative gradient of the function.
In the context of neural networks, the goal is to minimise the loss function, which measures the error between the predicted output and the desired output. The gradient of the loss function concerning the weights and biases is computed using backpropagation, and the weights and biases are updated in the opposite direction of the gradient to minimise the loss.
There are different variants of gradient descent, including:
- Batch Gradient Descent: In this method, the gradients are computed using the entire training dataset, and the weights and biases are updated after each epoch (one complete pass through the training data).
- Stochastic Gradient Descent (SGD): In SGD, the gradients are computed and the weights and biases are updated for each training example. This can lead to faster convergence but may also introduce more noise.
- Mini-batch Gradient Descent: This method is a compromise between batch gradient descent and SGD. The training data is divided into small batches, and the gradients are computed and weights updated for each mini-batch.
Optimisation techniques, such as momentum, adaptive learning rates such as the Adam and RMSProp and regularisation methods like L1, L2 and dropout, are often used in conjunction with gradient descent to improve the training process and prevent overfitting.
The training process is typically an iterative one, where the neural network is exposed to the training data multiple times and the weights and biases are updated in each iteration to minimise the loss function. The training process continues until the loss function converges or a predefined number of epochs is reached.
Types of Neural Networks in Machine Learning
Neural networks in Machine Learning come in various architectures and types, each designed to handle specific types of problems and data structures effectively. Here are some of the most common types of neural networks:
- Feedforward Neural Networks: Feedforward neural networks, also known as multi-layer perceptrons (MLPs), are the simplest and most fundamental types of neural networks. In these networks, information flows in one direction, from the input layer through the hidden layers to the output layer, without any cycles or loops. They are particularly well-suited for tasks such as pattern recognition, image classification, and data prediction.
- Recurrent Neural Networks (RNNs): Recurrent neural networks are designed to handle sequential data, such as text, speech, or time series data. Unlike feedforward networks, RNNs have connections that form loops, allowing them to maintain an internal state and process inputs sequentially. This makes them suitable for tasks like language modelling, machine translation and speech recognition.
- Convolutional Neural Networks (CNNs): Convolutional neural networks are particularly effective for processing data with a grid-like topology, such as images and videos. CNNs use convolutional layers that apply filters or kernels to the input data, enabling them to automatically learn and extract relevant features. They are widely used in computer vision tasks, including image classification, object detection, and semantic segmentation.
- Autoencoders: Autoencoders are a type of neural network that aims to learn efficient data encodings or representations. They consist of an encoder network that compresses the input data into a lower-dimensional representation and a decoder network that reconstructs the original input from this compressed representation. Autoencoders are commonly used for dimensionality reduction, data denoising, and unsupervised learning tasks.
- Generative Adversarial Networks (GANs): Generative Adversarial Networks (GANs) are a type of neural network architecture that consists of two competing networks: a generator and a discriminator. The generator network learns to generate new data samples that resemble the training data, while the discriminator network tries to distinguish between the real data and the generated samples. GANs are used for tasks such as image generation, style transfer, and data augmentation.
- Transformer Networks: Transformer networks are a type of neural network architecture that relies heavily on attention mechanisms to capture long-range dependencies in sequential data. They have been particularly successful in natural language processing tasks, such as machine translation, text summarisation, and language modelling. The Transformer architecture was introduced in the seminal "Attention is All You Need" paper.
Applications of Neural Networks in Machine Learning
Neural networks in Machine Learning have enabled machines to perform tasks that were once thought to be exclusive to human intelligence. Some of the most common and impactful applications of neural networks in machine learning include:
- Image Recognition and Computer Vision: Convolutional Neural Networks (CNNs) have been instrumental in advancing image recognition and computer vision capabilities. They are widely used for tasks such as object detection, facial recognition, image classification, and even medical image analysis.
- Natural Language Processing (NLP): Recurrent Neural Networks (RNNs) and Transformer models have been instrumental in natural language processing tasks, including language translation, text summarisation, sentiment analysis, and conversational AI. These models can understand and generate human-like text, enabling applications like chatbots and automated writing tools, for example, Open AI’s ChatGPT.
- Speech Recognition and Generation: Neural networks, particularly RNNs have transformed speech recognition and generation systems. They are used in applications such as voice assistants, automatic speech-to-text transcription, and text-to-speech synthesis. Top companies like Google, Amazon and Apple rely heavily on neural networks for their voice-based services like everyone’s favourite Alexa and Siri.
- Predictive Analytics and Forecasting: Neural networks are widely used for predictive analytics and forecasting in various domains, such as finance, sales, and supply chain management. They can analyse large datasets and identify complex patterns, making them valuable for tasks like stock market prediction, sales forecasting, and demand planning.
- Recommendation Systems: Neural networks power many modern recommendation systems used by companies like Netflix, Amazon, and Spotify. These systems analyse user preferences, behaviour, and contextual information to provide personalised recommendations for movies, products, or music.
- Autonomous Vehicles: Neural networks are at the heart of self-driving car technology, enabling vehicles to perceive their environment, detect obstacles, and make real-time decisions about navigation and control. Convolutional Neural Networks and Recurrent Neural Networks are used for tasks like object detection, lane recognition, and path planning.
- Gaming and Robotics: Neural networks have achieved remarkable success in gaming and robotics applications. They have been used to develop artificial intelligence agents that can play complex games like chess, Go, and video games at superhuman levels.
Similar Read: 10 Tips and Tricks for Developers of AI Applications in the Cloud
Advantages and Disadvantages
Neural networks in Machine Learning offer several advantages that have contributed to their rising adoption, but they also have some limitations that should be considered.
Advantages
- Ability to Learn Complex Patterns: Neural networks excel at recognising patterns in large and complex datasets. They can learn intricate non-linear relationships and make accurate predictions or classifications, even with noisy or incomplete data. This capability makes them well-suited for tasks like image recognition, speech processing, and data mining.
- Adaptability: Once trained, neural networks can adapt to new data and generalise well to unseen examples. This flexibility allows them to be applied to a wide range of problems and domains without the need for extensive manual feature engineering or rule-based programming.
- Parallel Processing: Neural networks can perform computations in parallel, making them efficient for processing large amounts of data. This parallel processing capability is particularly useful in applications that require real-time or near real-time performance, such as speech recognition or autonomous vehicle control.
- Fault Tolerance: Neural networks are inherently fault-tolerant, meaning that they can still function correctly even if some of their components (nodes or connections) are damaged or fail. This makes them more robust and reliable than traditional rule-based systems.
Disadvantages
- Black Box Nature: Neural networks are often criticised for being "black boxes" because it can be challenging to understand how they arrive at their decisions or predictions. This lack of interpretability can be a concern in applications where explainability is crucial, such as in medical diagnosis or financial decision-making.
- Overfitting: Neural networks can be prone to overfitting, which means that they model the training data too closely, including noise and irrelevant patterns, resulting in poor generalisation of new data. Techniques like regularisation, dropout, and early stopping are used to mitigate overfitting, but it remains a challenge.
- Requirement for Large Datasets: Neural networks often require large amounts of labelled training data to achieve good performance. Obtaining and preparing high-quality datasets can be time-consuming and expensive, particularly in domains where data is scarce or difficult to obtain.
- Computational Complexity: Training deep neural networks with many layers and parameters can be computationally intensive and require significant computational resources, such as powerful GPUs or distributed computing clusters. This can make the deployment and scaling of neural networks challenging in resource-constrained environments. To overcome this challenge, organisations can opt for cloud GPUs for machine learning. At Hyperstack, we offer high-performance GPU instances that can be rented on demand, providing a cost-effective GPU pricing model and scalable solution for training and deploying neural networks.
Future of Neural Networks in Machine Learning
Neural networks have traditionally been trained on specific tasks or modalities like image recognition and speech recognition. However, the future may see a greater emphasis on multimodal and multitask learning, where neural networks can process and learn from multiple modalities such as text, images and audio simultaneously and adapt to different tasks more efficiently, better mimicking the versatility of human intelligence.
We are also more likely to see the integration of Neural Networks with other AI techniques, such as symbolic reasoning, knowledge representations and planning algorithms. By combining the pattern recognition and learning capabilities of neural networks with other AI methods, researchers aim to develop more robust and versatile AI systems that can tackle a wider range of tasks and reason at a higher level.
Sign up for a free Hyperstack account today and experience the power of Machine Learning!
Similar Reads
FAQs
What are neural networks in machine learning?
Neural networks are computational systems inspired by the structure of the human brain. They comprise interconnected nodes, or neurons, organised in layers. These nodes process input data and transmit the results to the next layer. Through machine learning algorithms, neural networks can recognise patterns and relationships within data by adjusting the strengths of connections between neurons.
How do neural networks in machine learning work?
Neural networks function through layers of interconnected neurons. Input data is processed layer by layer, with each neuron applying weights to the inputs and passing the result to the next layer. Through training, these weights are adjusted to minimise errors, enabling the network to recognise complex patterns and make predictions.
What are the types of neural networks in machine learning?
Neural networks come in various types, including feedforward, convolutional, recurrent, and generative adversarial networks. Feedforward networks process data in a unidirectional manner, while convolutional networks excel in image recognition. Recurrent networks are specialised for sequential data, and generative adversarial networks are used for generating synthetic data.
Where are neural networks used?
Neural networks find applications across diverse domains such as image and speech recognition, natural language processing, medical diagnosis, financial forecasting, and robotics. They power technologies like virtual assistants, self-driving cars, recommendation systems, and medical imaging analysis.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 4 Apr 2025
4 Apr 2025