.png)
TABLE OF CONTENTS

Updated: 2 Oct 2024
In our series comparing two of the most popular language models, Mixtral-8x7B and LLaMA2-70B, we previously explored using Oobabooga's web-based text generation UI to run these LLMs in the cloud. We covered important aspects such as choosing the right GPU instance, setting up the required environment, deploying a cloud VM, starting the web UI and running a pre-trained model.
With the fundamentals out of the way, we now move forward on learning about the use of batching for GPU utilisation. In this next part of the series, we'll explore strategies for maximising throughput and getting the absolute most out of your GPU infrastructure when running cutting-edge LLM batch inference.
Use Case: Summarising Educational Nature Video Transcripts
For this tutorial, we'll use a real-world and interesting use case i.e. generating summaries for educational video transcripts about nature from the popular YouTube playlist on TED-Ed. The playlist covers fascinating topics like why animals form swarms, the three different ways mammals give birth, and other curiosities about the natural world. While highly informative, the full video transcripts can be quite long. The goal is to leverage the capabilities of large language models like Mixtral-8x7B and LLaMA2-70B to automatically generate concise 100-word summaries that extract the key facts and takeaways from each video transcript.
This use case provides a great benchmark for evaluating the text generation capabilities of large language models, as well as optimising their inference performance on GPUs through techniques like GPU batching. By the end of this tutorial, we'll be able to rapidly generate summaries for all 100 video transcripts in our dataset in a highly optimised and parallelised way, showcasing the power of models like Mixtral-8x7B and LLaMA2-70B.
Setting Up Jupyter Notebooks with GPU Acceleration
First, you'll need a Python environment configured with GPU acceleration, such as a cloud VM instance with one or more NVIDIA GPUs. For example, we use a beefy setup with 4 NVIDIA A100 80GB GPUs connected via PCIe for excellent latency and throughput, though you can use fewer GPUs as available. We'll work in Visual Studio Code with the GPU-powered VM instance remotely connected.

Getting Video Transcripts from YouTube
Our use case is to generate summaries for educational nature video transcripts from the popular TED-Ed YouTube channel. We scrape the video list and transcript data from the channel's website.
Using the “youtube-transcript-api” Python library, we can fetch the raw transcript text for any given YouTube video ID:
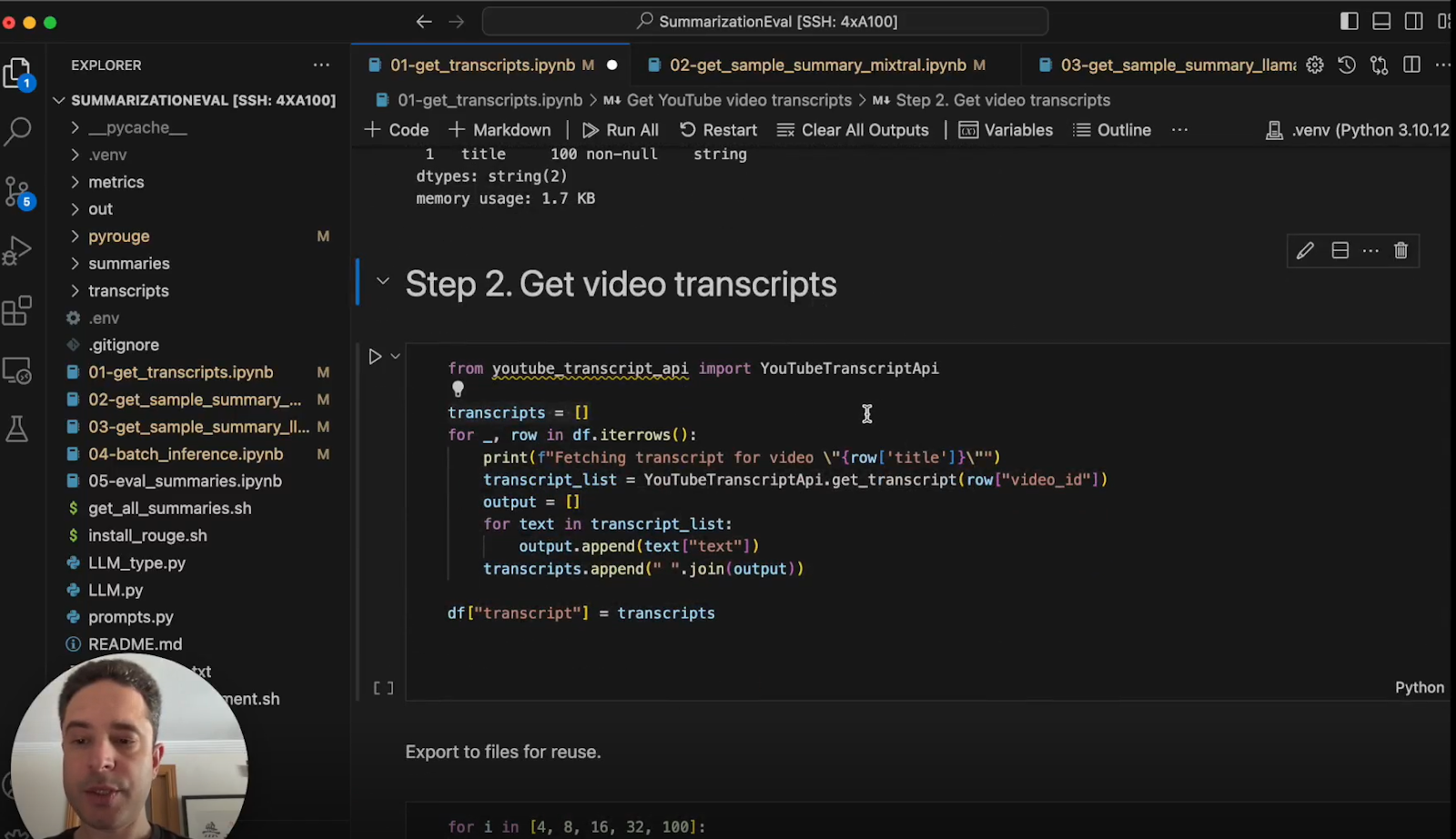
This returns the transcript as a list of dictionaries, which we can flatten into the full transcript text string. We'll export these 100 transcripts using Pandas into a CSV file for easy processing in the next step.
Performing LLM Inference to Obtain Summaries
We'll utilise two powerful open-source language models to generate summaries from the video transcripts: the 70 billion parametres LLaMA model from Meta and Mixtral-8x7 from Mistral.AI. We load these large models using the HuggingFace Transformers library. The key is to share the model across multiple GPUs using the” device_map” parameter. We also enable the “FlashAttention2” kernel for efficient GPU utilisation.
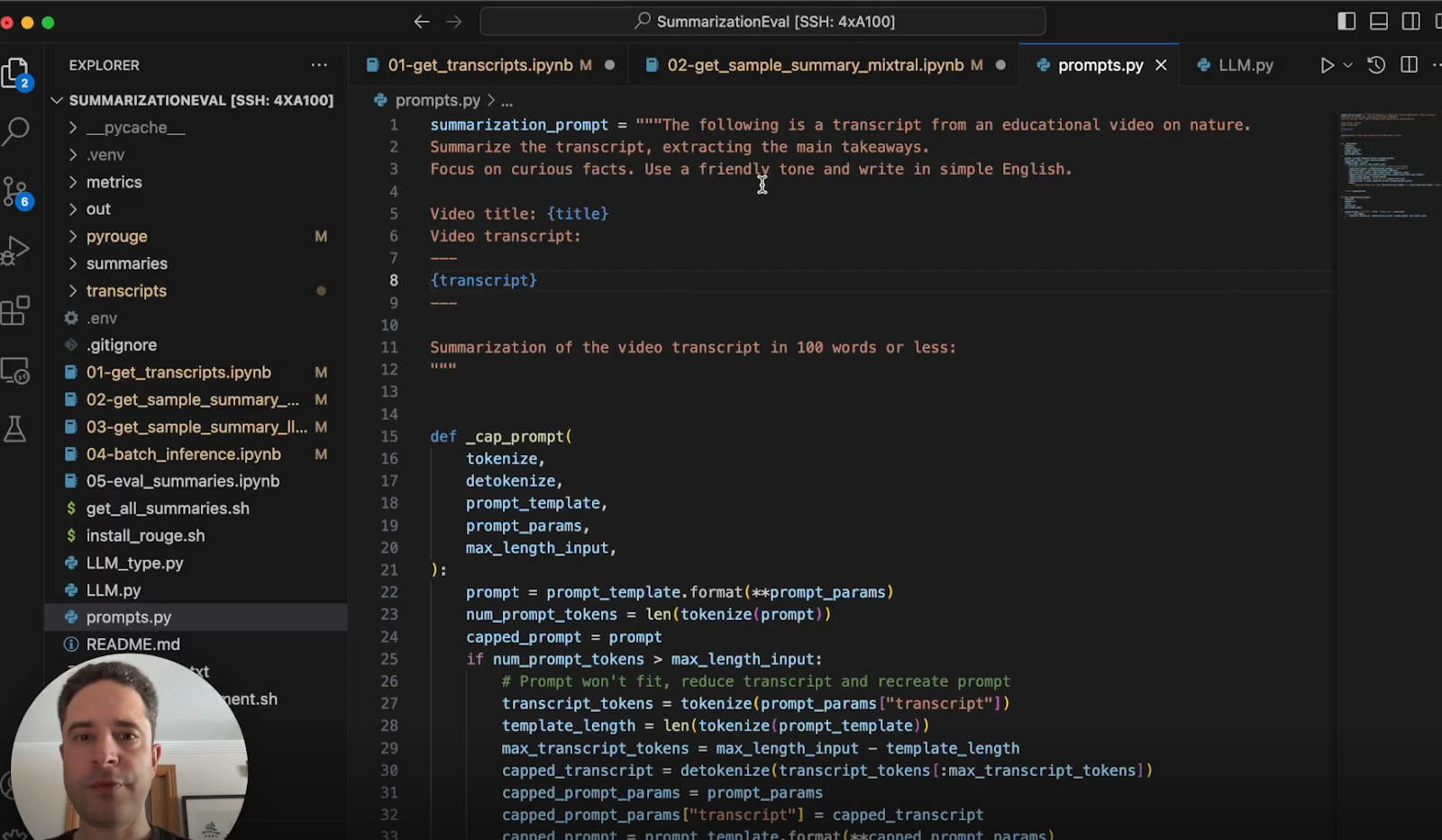
With the model loaded, we can now generate summaries for each video transcript by building a prompt combining a template and the transcript text:
“The following is a transcript from an educational video on nature. Summarise the transcript, extracting the main takeaways. Focus on curious facts. Use a friendly tone and write in simple English.”
This prompts the model to generate a summary extracting the key takeaways and interesting facts from the given video transcript, in a friendly tone aimed at educational content.
Batching Requests for Better GPU Utilisation
While this approach works for generating individual summaries, if we monitor LLM GPU utilisation during the inference, we see it is surprisingly low. To better optimise our hardware, we can take advantage of batch size and GPU memory - grouping multiple inference requests into one larger forward pass through the model. This allows us to feed more work to the GPU at once for better parallelisation.
We modify the code to make a batch of prompts as input, packing their tokens into a single inference request. So by increasing the batch size from 1 (no batching) to 2, 4, 8, 16, 32 and higher, we are feeding more parallel work to the GPU which can dramatically improve utilisation. However, larger batches also increase memory requirements, so there is a tradeoff in finding the optimal batch size for the available GPU memory.

Evaluating the Batching Performance
To systematically analyse the performance impact of batching, we run a series of experiments generating video summaries with different batch sizes from 1 to 64.
For each experiment, we record the overall tokens/second throughput achieved and plot the results for both the Mixtral-8x7B and LLaMA2-70B models:

As expected, we see that larger batch sizes yield significantly higher throughput, as we are better able to utilise the GPU's parallel computing capabilities.
Interestingly, for smaller batch sizes under 16, the smaller Mixtral model is faster than LLaMA. But as we increase the batch size to 32 and 64, the advantage flips and the larger LLaMa model starts to outperform, achieving over 1500 tokens/sec at the maximum 64 batch size.
We can visualise this crossover more clearly by plotting the speedup factor over ideal inference batching:
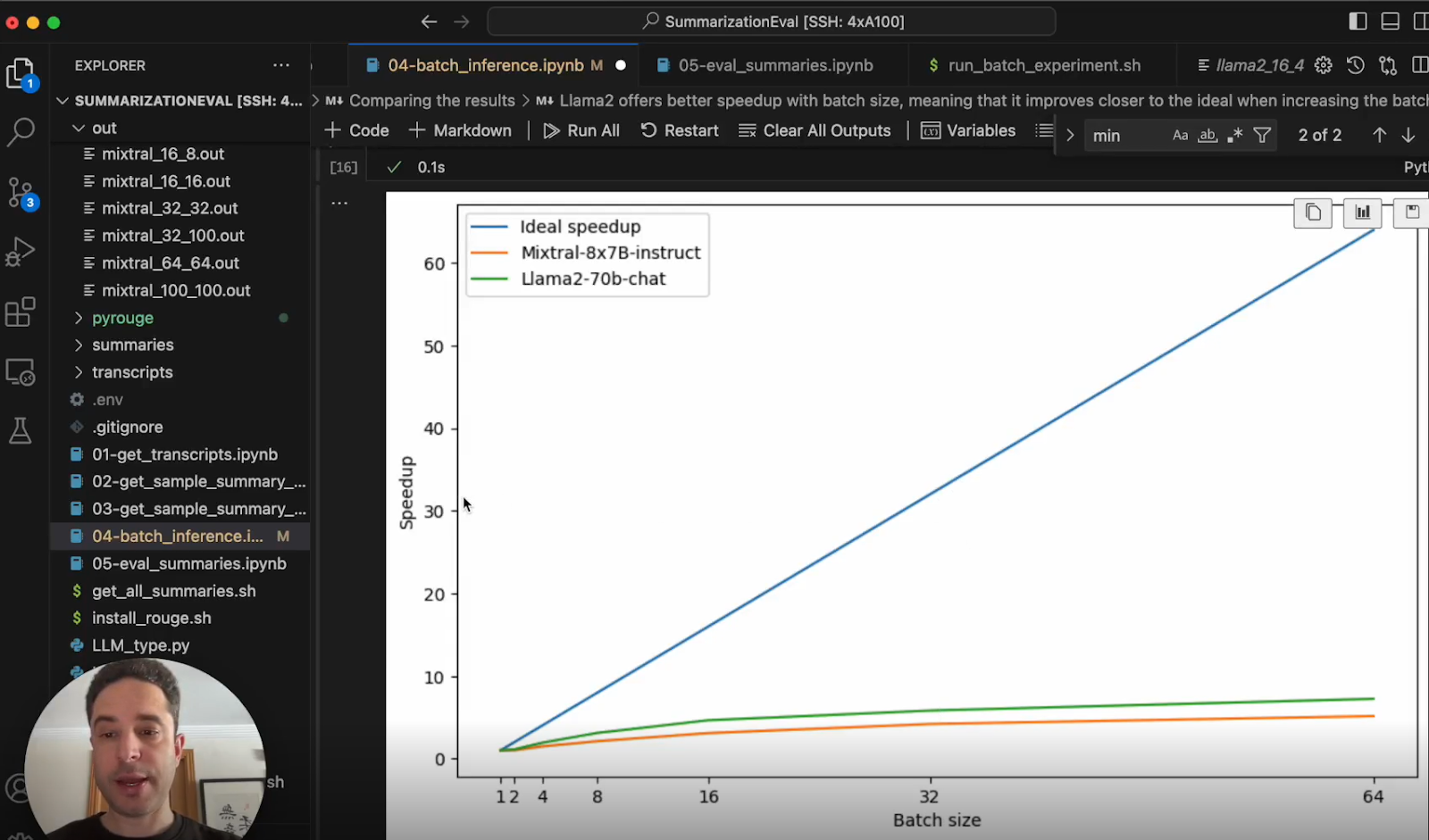
The green llama line stays closer to the ideal linear 32x speedup at batch size 32, compared to Mixtral which sees more diminishing returns from batching on the larger model.
This indicates that while all models benefit from batching to experience GPU parallelism, different models may scale differently.
Limitations of Batching
While extremely effective, batching does have its limits. If we try to batch too many requests together, we run into out-of-memory issues even on the NVIDIA A100 80GB GPUs used in this tutorial. For the 100 video transcripts, both models ran out of memory when trying to batch all of them together into one forward pass, despite the high GPU memory capacity.
So there is a tradeoff between batch size and memory usage that needs to be balanced. We can't pack infinite requests together, but we can always work towards finding an optimal batch size while staying within the available memory
Conclusion
In this tutorial, we learned about improving the inference performance of large language models like Mixtral-8x7B and LLaMA2-70B when running on GPU hardware. The key technique was batching - grouping multiple inference requests into one larger forward pass through the model.
Even simple batching strategies enabled massive speedups in throughput and much better utilisation of the GPU's parallel computing capabilities. While pushing too large of batch sizes can cause out-of-memory issues, a reasonable batch size like 32 yielded around 6x speedup over naive single-request inference.
However, focusing solely on throughput metrics is not enough. In the next part, we'll evaluate the quality of the summarisation outputs in this Mixtral-8x7B and LLaMA2-70B series!
Watch the full tutorial below
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 11 Apr 2025
11 Apr 2025