
TABLE OF CONTENTS
- What is Mistral NeMo?
- Features of Mistral NeMo
- Performance of Mistral NeMo
- Performance Observations
- Getting Started with Mistral NeMo on Hyperstack
- Watch Our Quick Platform Tour to Get Started with Hyperstack!
- FAQs
- What is Mistral NeMo?
- What languages does Mistral NeMO support?
- Can Mistral NeMO be fine-tuned for specific tasks?

Updated: 22 Apr 2025
NVIDIA H100 SXM On-Demand

Mistral has recently released its best new small model called Mistral NeMo, a 12B model featuring a 128k context length. What sets Mistral NeMo apart is its advanced reasoning, extensive world knowledge and exceptional coding accuracy. Mistral NeMo surpasses prominent models like Gemma 2 9B and Llama 3 8B in most benchmarks, even though it has a comparable or slightly larger model size. Continue reading this article as we explore its features, performance benchmarks and deployment.
What is Mistral NeMo?
Mistral NeMo is a state-of-the-art 12B small model developed by Mistral AI and NVIDIA. The model is released under the Apache 2.0 license. Mistral NeMo excels in various tasks, including reasoning, world knowledge application and coding accuracy. It uses a standard architecture that makes it easily adaptable as a drop-in replacement for systems currently using Mistral 7B.
Also Read: Meet Codestral Mamba: Mistral AI's Latest Model for Code Generation
Features of Mistral NeMo
The features of Mistral AI’s latest model NeMo include:
- Large Context Window: Mistral NeMo boasts a context window of up to 128k tokens that surpass many existing models. This extended context allows for better understanding and processing of long-form content, complex documents and multi-turn conversations.
- State-of-the-Art Performance: In its size category, Mistral NeMo offers top-tier performance in reasoning, world knowledge and coding accuracy.
- Quantisation Awareness: Trained with quantisation awareness, it supports FP8 inference without performance loss.
- Multilingual Capabilities: Mistral NeMo excels in multiple languages. Its proficiency spans various languages like English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic and Hindi.
- Function Calling: The model is trained on function calling, enhancing its ability to interact with and execute specific programmatic functions based on natural language inputs.
- Tekken Tokenizer: Mistral NeMO uses a new tokenizer called Tekken, based on TikToken. This tokenizer was trained in over 100 languages and offers improved compression efficiency for natural language text and source code compared to previous tokenizers.
- Efficient Code Compression: Tekken demonstrates approximately 30% higher efficiency in compressing source code and various languages, including Chinese, Italian, French, German, Spanish and Russian. It's 2x and 3x more efficient in Korean and Arabic respectively.
- Advanced Fine-tuning and Alignment: Mistral NeMo underwent a sophisticated fine-tuning and alignment phase. This resulted in enhanced capabilities for following precise instructions, reasoning, handling multi-turn conversations and generating code.
- Easy Integration: As a standard architecture model, Mistral NeMo can be easily integrated into existing systems as a direct upgrade or replacement for previous models like Mistral 7B.
Also Read: Mathstral: All You Need to Know About Mistral AI's New 7B Parameter Model
Performance of Mistral NeMo
Mistral AI NeMo demonstrates impressive performance across various benchmarks. The following table compares the Mistral NeMo benchmark with two recent open-source pre-trained models, Gemma 2 9B and Llama 3 8B:
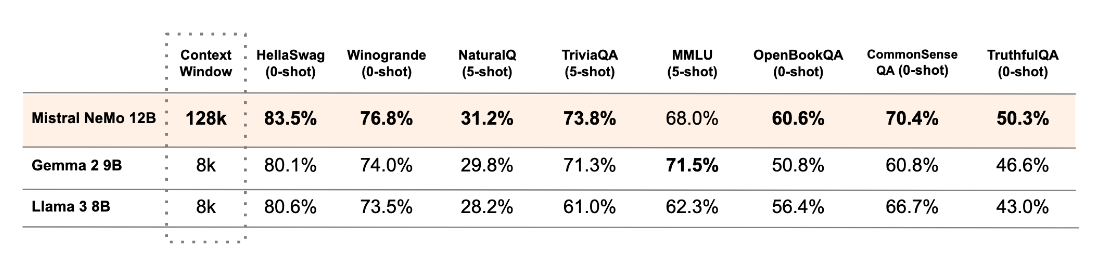
Source: https://mistral.ai/news/mistral-nemo/
Performance Observations
Based on the performance of Mistral AI NeMo, we could make several key observations:
- Mistral NeMo's 128k token context window is significantly larger than Gemma 2 9B and Llama 3 8B, which have 8k token windows. This extensive context allows Mistral NeMO to process and understand longer text sequences. This leads to better performance on tasks requiring long-range dependencies.
- Mistral NeMo outperforms Gemma 2 9B and Llama 3 8B in most benchmarks, despite having a similar or slightly larger model size. This suggests that the architecture and training methodology of Mistral NeMO are more effective.
- In zero-shot tasks like HellaSwag, Winogrande, OpenBookQA, CommonSense QA and TruthfulQA, Mistral NeMo consistently shows superior performance. This indicates strong generalisation abilities and a robust understanding of language and context without task-specific fine-tuning.
- For few-shot tasks (NaturalQ, TriviaQA, and MMLU), Mistral NeMo generally maintains its lead. This shows its ability to adapt to new tasks with minimal examples quickly.
- Mistral NeMo excels in knowledge-intensive benchmarks like TriviaQA and CommonSense QA, suggesting a strong grasp of world knowledge and common sense The model's strong performance in tasks like Winogrande and MMLU indicates advanced reasoning capabilities, crucial for complex language understanding and generation tasks.
- Mistral NeMO's higher score in TruthfulQA suggests it may be more reliable in providing accurate information, an important factor for real-world applications.
Getting Started with Mistral NeMo on Hyperstack
To get started with Mistral NeMo, follow the below steps:
- Download the model weights for both base and instruct versions from Mistral NeMo HuggingFace.
- Use mistral-inference to run the model for immediate testing and deployment.
- Adapt the model to specific tasks or domains using mistral-finetune.
- Access Mistral NeMO on “La Plateforme” under the name open-mistral-nemo-2407.
- The model is available as an NVIDIA NIM inference microservice container, accessed and deployed from ai.nvidia.com.
On Hyperstack, after setting up an environment, you can download the Mistral NeMO model from Hugging Face and load the model into the Web UI. Our powerful hardware resources make it easy and budget-friendly to fine-tune, inference and experiment with Mistral NeMO. You can fine-tune it with our high-end NVIDIA GPUs like the NVIDIA A100 or the NVIDIA H100 SXM and perform inference with the NVIDIA A100 or NVIDIA L40. Our cost-effective GPU Pricing ensures you only pay for the resources you consume.
Watch Our Quick Platform Tour to Get Started with Hyperstack!
FAQs
What is Mistral NeMo?
Mistral NeMo is a cutting-edge 12B language model developed by Mistral AI and NVIDIA. Released under the Apache 2.0 license, it features a 128k token context length, enabling it to handle much longer texts than many earlier models.
What languages does Mistral NeMO support?
Mistral NeMO supports a wide range of languages including English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
Can Mistral NeMO be fine-tuned for specific tasks?
Yes, Mistral NeMO is designed to be easily adaptable and can be fine-tuned for various applications using tools like mistral-finetune.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

