
TABLE OF CONTENTS

Updated: 11 Feb 2025
NVIDIA A100 GPUs On-Demand
Albert Einstein happily talking about his childhood in a video or Marilyn Monroe in her iconic white dress chatting about her love for Chanel No.5. You won't find these scenes in any archive footage or historical records. Why? Because they were never actually recorded. Yet now, thanks to cutting-edge Generative AI, we can create these lifelike scenarios as if they were real. With famous quotes and documented interviews from these figures, we can actually bring them back to life with AI, using their images to create videos of them speaking with various emotions.
To give you a clear understanding of how this works, we're going to take you through the entire process step by step. In this tutorial, we'll show you how to use AI to transform still images into realistic videos. We'll be using powerful GPU resources available on the Hyperstack platform to ace this complex AI task quickly and efficiently.
Tools and Setup
For this project, we leveraged two primary technologies:
- DreamTalk: This is a research preview by authors from Tsinghua University, Alibaba Group and Huazhong University of Science and Technology. It allows us to generate videos from still images and audio recordings.
- OpenVoice: An open-source package developed by researchers from MIT, MyShell and Tsinghua University which enables voice cloning.
Our experiments were conducted using an NVIDIA A100 GPU with 80GB PCIe on the Hyperstack platform. We used Jupyter notebooks to run our code which we'll be explaining throughout this tutorial.
Acknowledgments
We extend our heartfelt gratitude to the authors of the DreamTalk research for generously providing access to their denoising and renderer networks. Their contributions have been invaluable in showcasing the capabilities of this technology.
Use Case
Our goal is to showcase the potential of AI video generation. We'll bring to life two of the most iconic figures of the 20th century: the brilliant physicist Albert Einstein and the iconic actress Marilyn Monroe. These case studies demonstrate how we can combine historical imagery, authentic audio and cutting-edge AI to create lifelike animations of these icons.
Bringing Einstein to Life
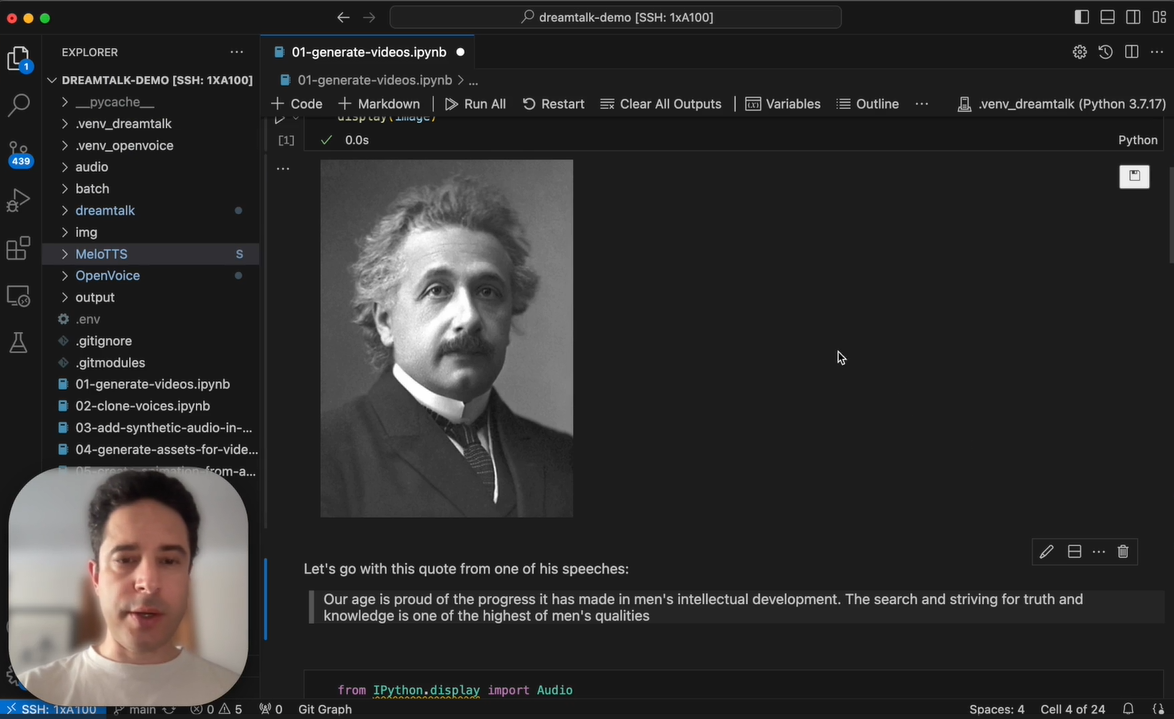
We started with a public domain image of a young Albert Einstein sourced from Wikimedia Commons. To accompany this image, we used a snippet from one of Einstein's surviving audio recordings from 1943. The quote we chose was:
"Our age is proud of the progress it has made in men's intellectual development. The search and striving for truth and knowledge is one of the highest of men's qualities."
Using DreamTalk, we were able to generate a video of the young Einstein saying these words. The process was remarkably quick, taking just a few seconds on our NVIDIA A100 GPU. The result was a quite realistic (though not perfect) animation of Einstein speaking with synchronised lip movements and subtle facial expressions.
Animating Marilyn Monroe
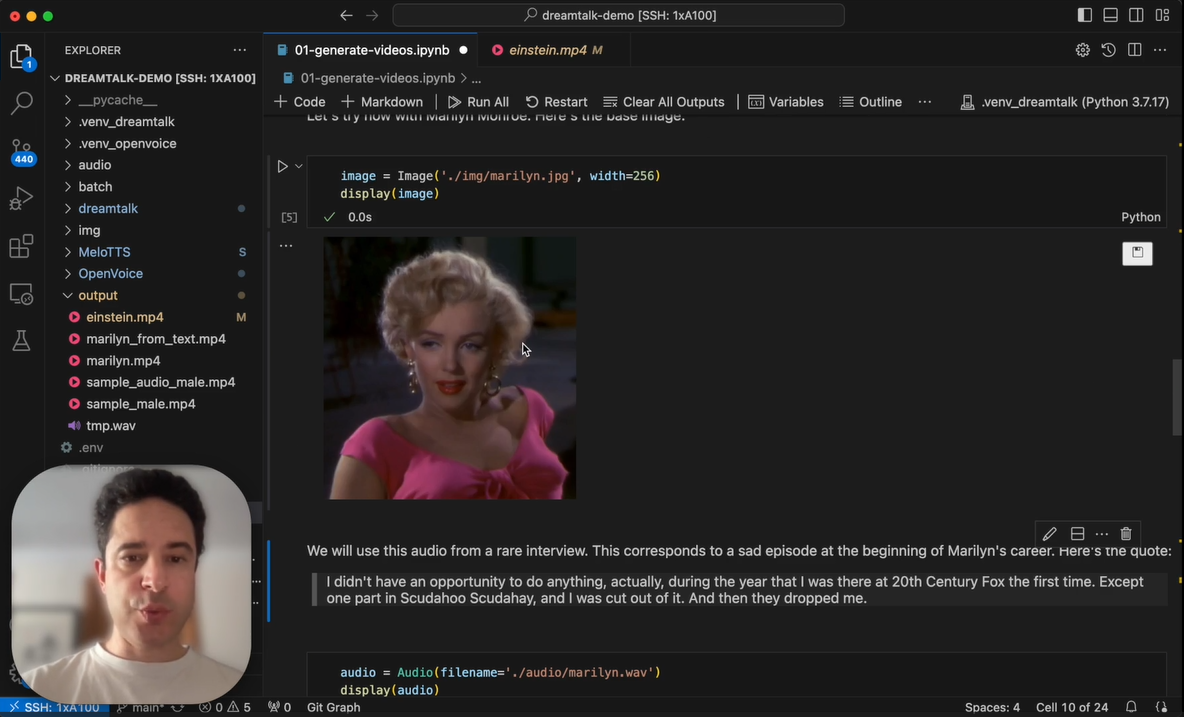
For our second subject, we chose an image of Marilyn Monroe from the movie "Niagara," also sourced from Wikimedia Commons. We paired this with an audio clip from a rare interview where Monroe laments one of her earlier and minor roles:
"I didn't have an opportunity to do anything, actually, during the year that I was there at 20th Century Fox the first time, except one part in Scudda-hoo Scudda-hay, and I was cut out of it. And then they dropped me."
When generating this video, we added an extra parameter to DreamTalk, specifying "sad" as the emotion. This resulted in a video where Monroe's facial expressions and movements conveyed a somber and melancholic tone that matched the content of her words.
Similar Read: How to Train Generative AI for 3D Models
Understanding DreamTalk
To appreciate how DreamTalk achieves these results, let's get into the details. The system consists of four main components:
- Denoising Network: This is a diffusion model that generates predicted motion with lip-syncing and head movements.
- Style-aware Lip Expert Module: This ensures that the generated lips are synchronised with the input audio.
- Style Predictor: Trained on combinations of audio and faces, this creates a vector representation of expressiveness.
- Renderer Module: This combines the movement representation with the original portrait to create the final video.
The system is trained on reference videos of people expressing different emotions such as fear, happiness, sadness, grief and more which informs the model to generate expressive facial movements as we witnessed in Marilyn Monroe’s case.
Synthetic Audio Generation
While bringing Einstein and Monroe to life from existing recordings was impressive, we wanted to push the technology further. We found a quote attributed to Monroe for which no audio recording exists. The quote is quite impactful as it says “An actress is not a machine, but they treat you like a machine, a money machine.” To make Monroe "say" these words, we turned to voice cloning technology with OpenVoice.
Understanding OpenVoice
OpenVoice works in two main steps as mentioned below:
- Text-to-Speech Conversion: It starts by converting the text into audio using a base text-to-speech model. In this case, we used MeloTTS which supports multiple accents of the English language.
- Voice Cloning: The system then applies a "tone color" extracted from an original sample of Monroe's voice to the generated audio, effectively transforming it to sound like Monroe's voice.
The result was a synthetic audio clip that sounded remarkably like Monroe saying words she never actually spoke in real life.
Combining Technologies
With our synthetic audio in hand, we returned to DreamTalk to generate a video of Monroe speaking these words. The final result was a video of Monroe animated from a still image to speaking words she never actually said in a voice that sounds convincingly like her own. The subtle and sweet voice which made her distinct from her peers.
Watch the full video on our YouTube channel for results!
Performance Comparisons
We also ran some performance tests to compare GPU and CPU processing times. Using the NVIDIA A100 GPU, we were able to generate videos about 8 times faster than on a CPU (AMD EPYC 7763). On the GPU, we achieved real-time performance, generating 15 seconds of video in about 15 seconds.
Ethical Considerations
While the results of our experiment are exciting from a technological standpoint, they also raise important ethical questions. The ability to make historical figures "say" things they never actually said opens up the door for the spread of misinformation and deepfakes, which has become quite relevant in today’s time. It's crucial to approach these technologies responsibly.
In our experiment, we used actual quotes from Albert Einstein and Marilyn Monroe and we've been transparent about the synthetic nature of the Monroe audio. However, it's easy to see how this technology could be misused to spread false information or manipulate public opinion. As developers and users of AI technology, we have a responsibility to consider the potential impacts of our work and to use these tools ethically.
Final Thoughts
Looking ahead, the potential applications of this technology are vast. In education, we could create interactive historical figures to make learning more engaging. In entertainment, we could bring our beloved characters back to the screen or create entirely new performances from late actors. To be more inclusive, we could generate sign language videos from text that make content more accessible to the deaf and hard of hearing. However, each of these applications comes with its own set of ethical considerations that need to be carefully looked after.
What’s Next
In our next installment, we'll explore even more advanced applications by creating a pipeline for generating videos from synthetic still images of people. Until then, we encourage you to experiment with these technologies responsibly and always keep in mind the potential impacts of your creations. Get started today with Hyperstack to accelerate AI innovation!
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week


 7 Apr 2025
7 Apr 2025