On December 6, Meta surprised the AI community by unexpectedly releasing Llama 3.3, a significant advancement in open-source AI. Llama 3.3 achieves outstanding results across various applications, including instruction following, coding, multilingual tasks and more.
But that is not the only surprising part, the new Llama 3.3 model delivers 405B-level performance without the 405B-level price tag. Keep reading as we explore Llama 3.3's key features, training and how Meta continues to lead in sustainable AI innovation with Llama 3.3.
Llama 3.3 is a 70-billion parameter, instruction-tuned model optimised for text-only tasks. It delivers improved performance compared to Llama 3.1 70B and Llama 3.2 90B in text-based applications. For certain use cases, Llama 3.3 70B even match the performance of the much larger Llama 3.1 405B. Unlike previous versions, Llama 3.3 70B is available only in its instruction-tuned form, meaning it has been fine-tuned specifically for following instructions and a pre-trained version is not provided.
Llama 3.3 features include the following:
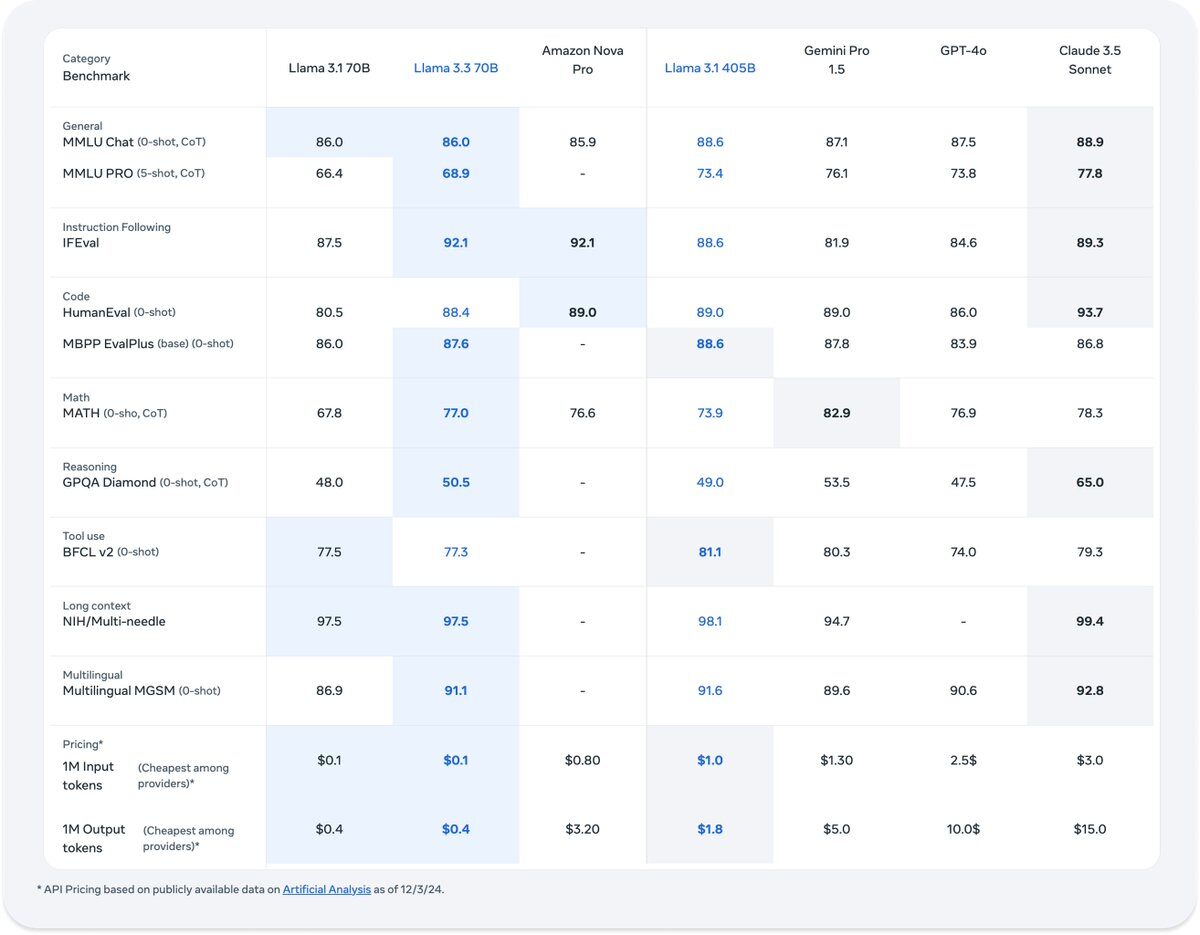
Llama 3.3 shows strong performance across various benchmarks [see benchmarks below], leading in categories such as instruction following, coding and multilingual reasoning. It achieves notable results in tasks like HumanEval, MBPP EvalPlus and IFEval, showing its ability to handle code and instruction-following tasks effectively.
Source: https://x.com/AIatMeta/status/1865079067390956006?t=CzoYUdPOUBvjmz81E50ZTA&s=19
See the below metrics to find Llama 3.3 performance across various benchmarks:
While larger models such as Llama 3.1 405B or Claude 3.5 Sonnet occasionally outperform Llama 3.3 in certain areas, Llama 3.3 remains a competitive and reliable choice for a wide range of applications.
Some of the key intended use cases for Llama 3.3 mode include:
The development of Llama 3.3 was no small feat, Llama 3.3 70B requirements were high. The latest Meta model was trained using an impressive 39.3 million GPU hours on NVIDIA H100 80GB GPUs, one of the most powerful GPUs in the market. The NVIDIA H100 GPUs with a Thermal Design Power (TDP) of 700W were imperative in managing the massive computational demands required to fine-tune and optimise the model’s performance.
Instantly access NVIDIA H100 GPUs on Hyperstack to experiment with AI models like Llama 3.3. Sign up here to get started!
The training process was extensive, leveraging advanced techniques such as reinforcement learning with human feedback (RLHF) and supervised fine-tuning. These methods ensured Llama 3.3 could handle complex tasks with high precision while aligning with human expectations. For Llama 3.3’s 70B parameter version, the training specifically required 7.0 million GPU hours, showing us how Meta achieves efficiency without compromising quality.
Despite the significant computational demands, Meta has ensured that the environmental impact of training remains minimal. The location-based greenhouse gas emissions for Llama 3.3’s training were estimated at 11,390 tons CO2eq with 2,040 tons CO2eq specifically attributable to the 70B parameter model. However, since 2020 Meta has achieved net-zero greenhouse gas emissions in its global operations by matching 100% of its electricity use with renewable energy sources. As a result, the total market-based greenhouse gas emissions for training Llama 3.3 stand at 0 tons CO2eq.
Llama 3.3 is a highly cost-effective model. It offers a pricing structure that is significantly more affordable compared to other advanced models. With input tokens priced at just $0.1 per million and output tokens at $0.4 per million, Llama 3.3 delivers excellent value. For comparison, models like GPT-4o and Claude 3.5 Sonnet can cost up to 10 to 15 times more per token. We can say that Llama 3.3 is undoubtedly an ideal choice for developers seeking powerful AI capabilities without breaking the budget.
On Hyperstack, getting started with Llama 3.3 is a straightforward process. After setting up your environment, you can easily download the Llama 3.1 model from:
Once downloaded, you can launch the web UI and load the model seamlessly. Hyperstack's powerful resources make it an ideal platform to fine-tune and experiment with capable open-source AI models like Llama 3.3. We recommend using NVIDIA H100 PCIe or NVIDIA SXM H100 GPUs for Llama 3.3 70B on Hyperstack.
Sign up now to get started with Hyperstack. To learn more, you can watch our platform demo video here.
Llama 3.3 is a 70-billion parameter, instruction-tuned AI model optimised for text-based tasks like coding, multilingual tasks, and instruction following.
Llama 3.3 was released on December 6, 2024 by Meta.
Llama 3.3 delivers superior performance at a lower cost compared to Llama 3.1 70B and Llama 3.2 90B, especially in instruction-following tasks.
Yes, Llama 3.3 supports multiple languages, ensuring broad usability in diverse linguistic environments, with exceptional performance in tasks requiring multilingual reasoning.
Llama 3.3 offers performance similar to larger models but at a fraction of the cost, with affordable token prices for developers.
Llama 3.3 was trained using 39.3 million GPU hours on NVIDIA H100 GPUs, incorporating reinforcement learning with human feedback and supervised fine-tuning.
Yes, you can download and run Llama 3.3 on Hyperstack using NVIDIA H100 GPUs for efficient fine-tuning and experimentation.
{kind=link}