

TABLE OF CONTENTS
NVIDIA H100 GPUs On-Demand
In our latest article, we explore how to deploy and use Meta’s newly released NotebookLlama on Hyperstack. This open-source AI tool automatically transforms PDFs into podcasts, leveraging Meta's advanced Llama models (Llama 3.2, 3.1) and the Parler text-to-speech model. Our step-by-step tutorial guides you through setting up a virtual machine, configuring the environment, and running NotebookLlama to create audio content effortlessly.
Meta has just released NotebookLlama, an AI-tool that automatically creates podcasts from PDF files. This tool is an open-source alternative to the Audio Overview feature in Google's Notebook LM. NotebookLlama leverages the cutting-edge capabilities of Meta's Llama family of models, including Llama 3.2, Llama 3.1 and the open-source Parler text-to-speech model. Everyone across the AI space is excited to experiment with this advanced model. If you’re also looking to get started, you’re at the right place.
Our latest tutorial below explores how to deploy and use Notebook Llama on Hyperstack.
How to Get Started with Notebook Llama
Let's walk through the step-by-step process to get started with Notebook Llama on Hyperstack:
Step 1: Accessing Hyperstack
- Visit the Hyperstack website and log in to your account.
- If you don't already have an account, you'll need to create one and set up your billing information. Check our documentation to get started with Hyperstack.
- Once logged in, you'll enter the Hyperstack dashboard, which overviews your resources and deployments.
Step 2: Deploying a New Virtual Machine
Initiate Deployment
- Navigate to the "Virtual Machines" section and click "Deploy New Virtual Machine."
- Click it to start the deployment process.
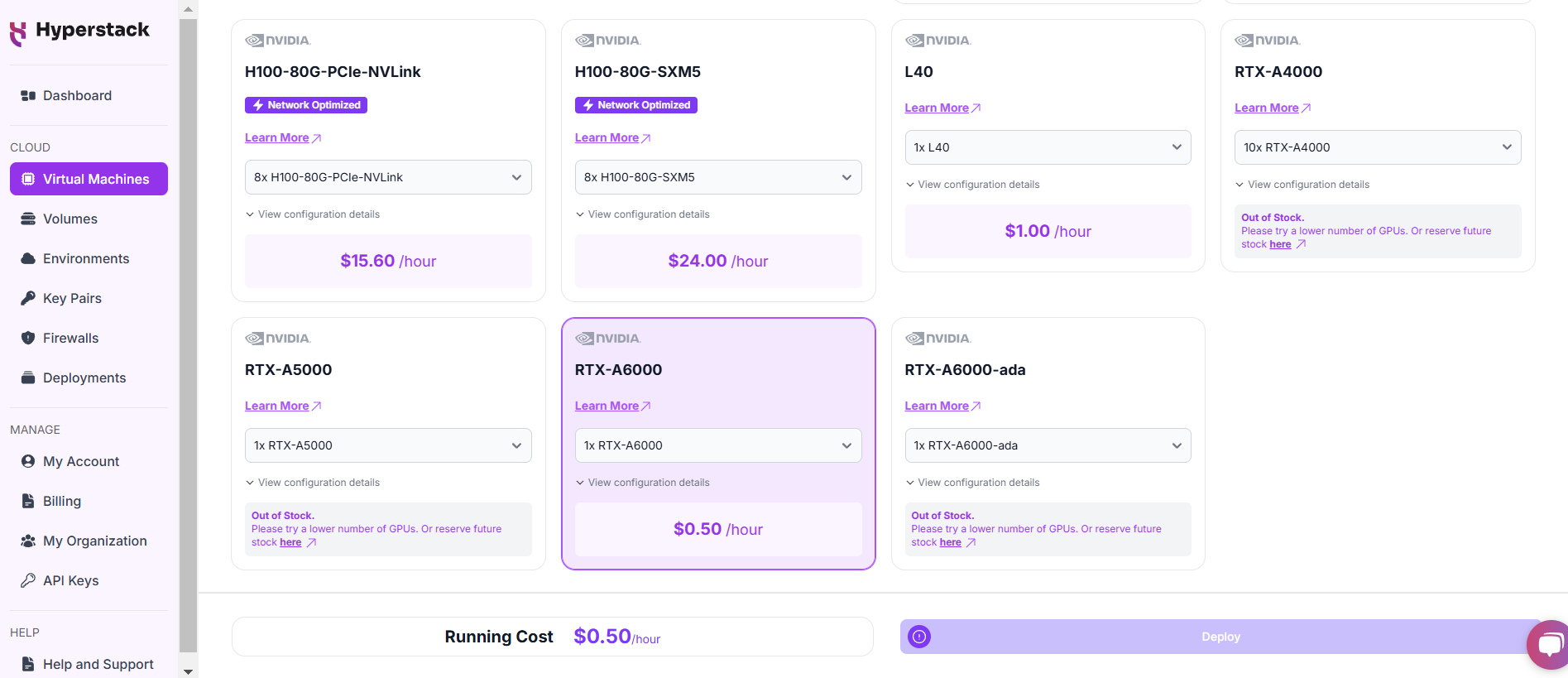
Select Hardware Configuration
- For using the smaller Llama 1B and 8B Llama models, we recommend choosing the NVIDIA RTX A6000 x1 for an affordable GPU. For faster processing speeds or if you are using the larger Llama 70B model we recommend the NVIDIA A100 x2.
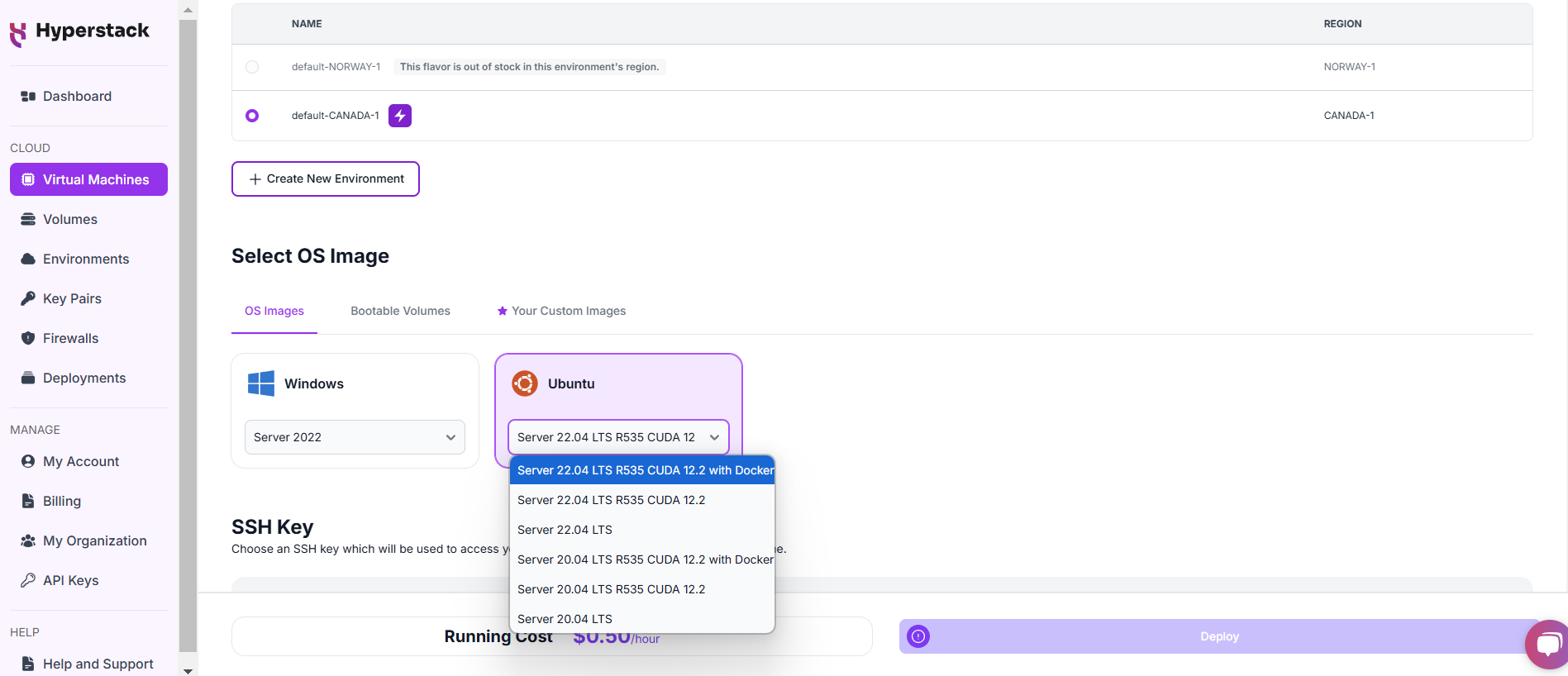
Choose the Operating System
- Select the "Server 22.04 LTS R535 CUDA 12.2 with Docker".
- This image comes pre-installed with Ubuntu 22.04 LTS, NVIDIA drivers (R535), CUDA 12.2, providing an optimised environment for AI workloads.
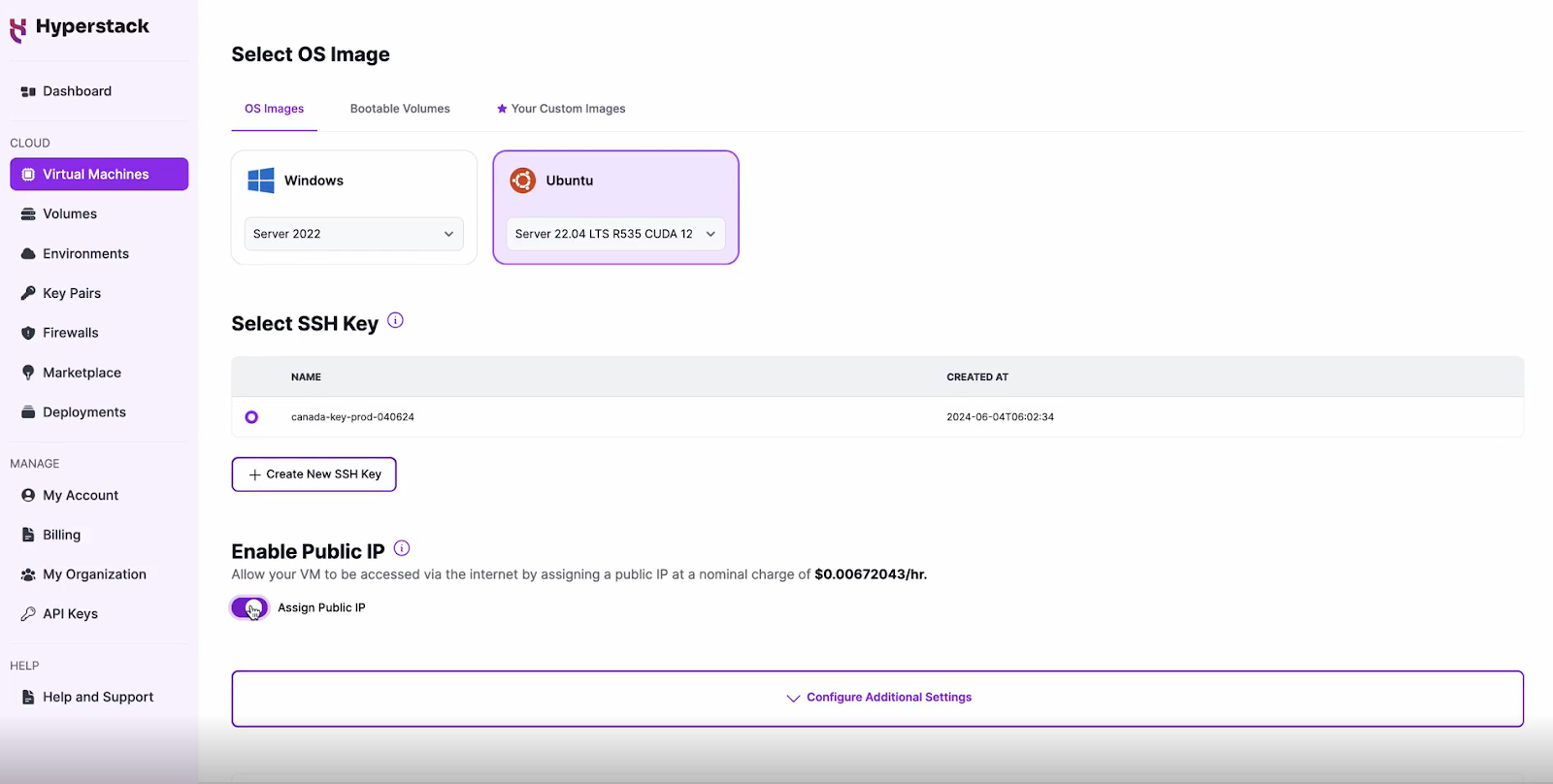
Select a Keypair
- Select one of the keypairs in your account. If you don't have a keypair yet, see our Getting Started tutorial for creating one.
Network Configuration
- Ensure you assign a Public IP to your Virtual machine.
- This allows you to access your VM from the internet, which is crucial for remote management and API access.
Enable SSH Access
- Make sure to enable an SSH connection.
- You'll need this to connect and manage your VM securely.
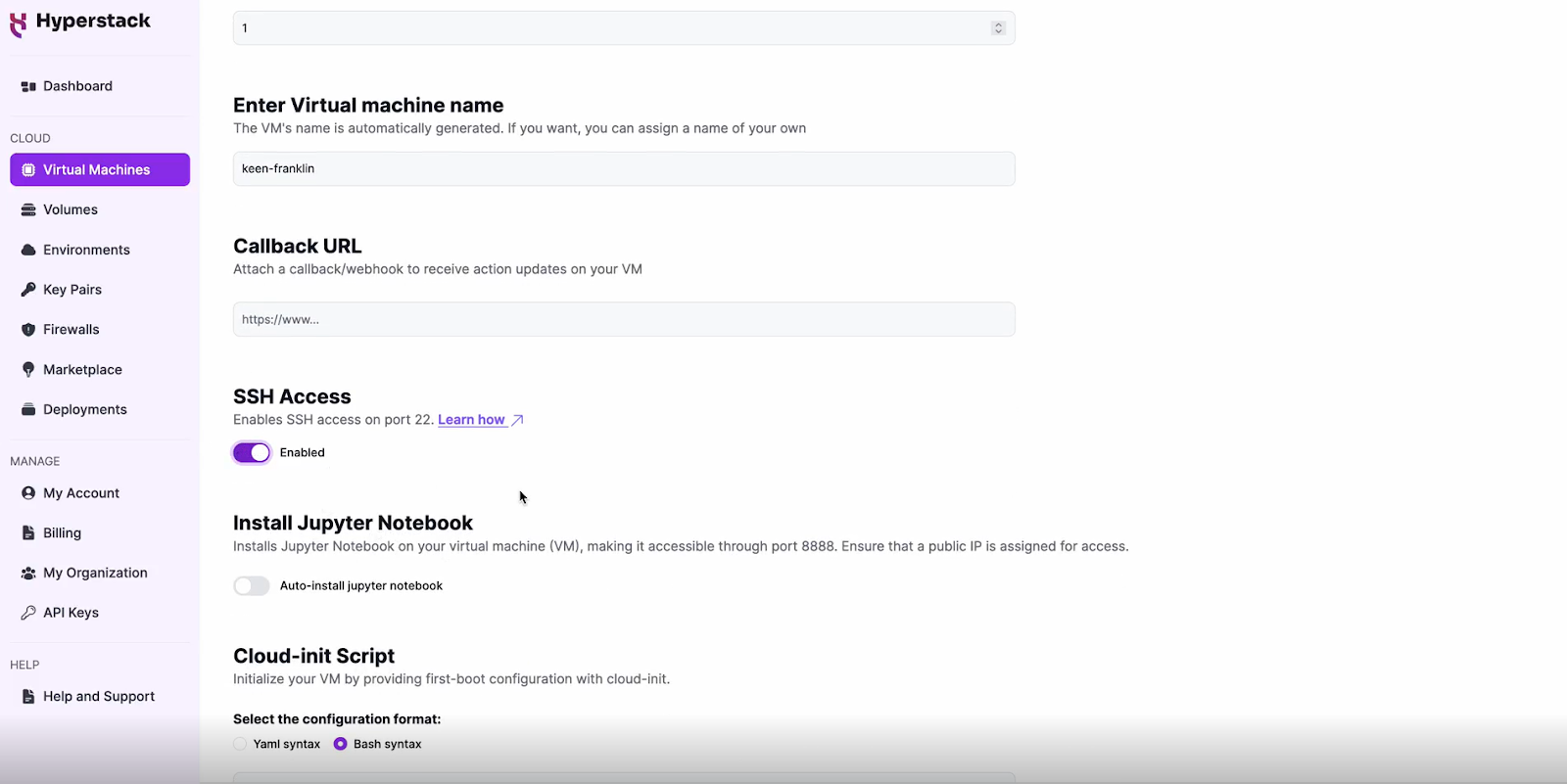
Configure Additional Settings
- Look for the "Configure Additional Settings" section and click on it.
- Here, you'll find the 'Install Jupyter Notebook' toggle. Enable this and set a password which you will need later.

Please note: This will open port 8888 to the public internet, allowing anyone with the public IP address and port number to access the dashboard. If you don't want this, you can restrict the IP addresses that can access the VM on port 8888 (see instructions here)
Review and Deploy the Script
- Double-check all your settings.
- Click the "Deploy" button to launch your virtual machine.
DISCLAIMER
This tutorial will only enable Notebook Llama once for demo-ing purposes. For production environments, consider using production-grade deployments with secret management, monitoring etc.
Step 3: Setting Up the Model
- The VM will configure install libraries and install the Jupyter Notebook server. This will take about 5 - 10 minutes.
Step 4: Accessing the Jupyter Notebook server
Once the initialisation is complete, you might need to reboot your VM to allow GPU access for your Jupyter Notebook server
ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address]
# Once connected through SSH
sudo reboot
Afterwards, you can access your Jupyter Notebook server. If you are having any issues, please check out our Troubleshooting tips below.
Option 1: Connect via public IP
If you used the default settings, use the following steps to connect with the Jupyter Notebook server
- Open a browser on your local machine
- Go to https://[public-ip]:8888/lab (make sure to add the s in https)
Option 2 Connect via SSH tunnel
- Open a terminal on your local machine.
- Use the command
ssh -i [path_to_ssh_key] -L 8888:localhost:8888 [os_username]@[vm_ip_address] # e.g: ssh -i /users/username/downloads/keypair_hyperstack -L 8888:localhost:8888 ubuntu@0.0.0.0 - Replace username and ip_address with the details provided by Hyperstack.
- Open a browser on your local machine
- Go to https://localhost:8888/lab (make sure to add the s in https)

Afterwards, enter your password you created in the steps above.
If you see any SSL warnings, you can skip them for now. They are related to the self-signed certificates being used for the HTTPS connection. For more info on this and its potential risks, see this blog.
Run Notebook Llama
Introduction
Notebook Llama enables you to transform any PDF into a podcast using open-source models in four steps:
- PDF Pre-processing: Upload a PDF, extract the text using PyPDF2, and save it as a .txt file for processing.
- Transcript Writer: Use a Llama LLM to generate a podcast-ready transcript from the cleaned text.
- Transcript Rewriter: Refine the transcript with a Llama LLM for enhanced narrative quality and TTS readiness.
- Text-to-Speech (TTS) Workflow: Convert the polished transcript into audio with the suno/bark or parler-tts models, completing the podcast creation.
Below we describe the exact steps of running these notebooks, including a couple of fixes that are needed (at the time of writing).
If you want to get started faster. Refer to the final notebooks below.
Running Notebook 1 of 4 - PDF pre-processing
Once you open the Jupyter Notebook server, use the following steps to
- Enter the password you used in 'Deploying your Virtual Machine'
- Click on the 'Terminal' Icon in the Launcher. Alternatively, click in the top-left corner on: File > New > Terminal

- Run the following command in the terminal
# Install Git apt-get update apt-get install git -y # Clone repository cd home git clone https://github.com/meta-llama/llama-recipes - Navigate to the folder /home/llama-recipes/recipes/quickstart/NotebookLlama in the sidebar menu on the left.

- Open requirements.txt by double-clicking on the file
- Comment on the third and last line, so your requirements.txt is as follows. We do not need a new PyTorch installation as our Jupyter Notebook installation comes with PyTorch already installed!
## Core dependencies PyPDF2>=3.0.0 # torch>=2.0.0 transformers>=4.46.0 accelerate>=0.27.0 rich>=13.0.0 ipywidgets>=8.0.0 tqdm>=4.66.0 # Optional but recommended jupyter>=1.0.0 ipykernel>=6.0.0 # Warning handling # warnings>=0.1.0 - Save the file with CTRL + S (or CMD + S on MacOs). Alternatively, click on File > Save Text in the top-left corner.
- Go back to /home/llama-recipes/recipes/quickstart/NotebookLlama
- Open the first notebook: Step1- PDF-Pre-Processing-Logic

- Add !pip install -r requirements.txt to the first cell. So your first cell should look like this:
!pip install PyPDF2 !pip install rich ipywidgets !pip install -r requirements.txt - To use these models you need to request gated access:
- Request access here for the default small models:
- Create a HuggingFace token to access the gated model, see more info here.
- You can also use a larger model (if you are using a more performant flavour like the 2xA100). Simply replace the 'DEFAULT_MODEL' variable in the Jupyter Notebook. Make sure to request gated access to the model. For example, use this code inside the Jupyter Notebooks to use the 70B model: DEFAULT_MODEL= "meta-llama/Llama-3.1-70B-Instruct"
- To set your HugginFace token, add the token to your environment variable with the code os.environ["HF_TOKEN"] = "[replace-with-your-token]". The third cell should look like this:
import PyPDF2 from typing import Optional import os import torch from accelerate import Accelerator from transformers import AutoModelForCausalLM, AutoTokenizer from tqdm.notebook import tqdm import warnings warnings.filterwarnings('ignore') os.environ["HF_TOKEN"] = "[replace-with-your-token]" - Fix the output path in cell 7. So your cell 7 should look like this:
INPUT_FILE = "./resources/extracted_text.txt"
CHUNK_SIZE = 1000 chunks = create_word_bounded_chunks(extracted_text, CHUNK_SIZE) num_chunks = len(chunks) processed_text = [] - Fix the variables in cell 17. So your cell 17 should look like this:
# Extract metadata first print("Extracting metadata...") metadata = get_pdf_metadata(pdf_path) if metadata: print("\nPDF Metadata:") print(f"Number of pages: {metadata['num_pages']}") print("Document info:") for key, value in metadata['metadata'].items(): print(f"{key}: {value}") # Extract text print("\nExtracting text...") extracted_text = extract_text_from_pdf(pdf_path) # Display first 500 characters of extracted text as preview if extracted_text: print("\nPreview of extracted text (first 500 characters):") print("-" * 50) print(extracted_text[:500]) print("-" * 50) print(f"\nTotal characters extracted: {len(extracted_text)}") # Optional: Save the extracted text to a file if extracted_text: output_file = './resources/extracted_text.txt' with open(output_file, 'w', encoding='utf-8') as f: f.write(extracted_text) print(f"\nExtracted text has been saved to {output_file}") - Run all commands inside the Notebook. Your last cell should look like the image below.

- Once your script is finished, close the notebook by clicking on File > Closed and Shut Down Notebook. Confirm the closing of the notebook by clicking OK on the confirmation dialog.

Running Notebook 2 of 4 - Transcript writer
- Go to your 'Home' page in your Jupyter Notebook. This should be the previous tab in your browser.
- Navigate to the folder /home/llama-recipes/recipes/quickstart/NotebookLlama in the sidebar menu on the left.

- Open the second notebook: Step-2 Transcript-Writer
- Change the second cell by:
- Adding the HuggingFace token for gated access of the Llama models
- Changing the MODEL in the second cell if you are using the small Llama models:
import os os.environ["HF_TOKEN"] = "[your-hf-token]" MODEL = "meta-llama/Llama-3.1-8B-Instruct"
- Change path used for the INPUT_PROMPT in cell 5:
# Extract metadata first INPUT_PROMPT = read_file_to_string('./resources/clean_extracted_text.txt') - Run all cells in the notebook
- The final cell should look like this:

- Once your script is finished, close the notebook by clicking on File > Closed and Shut Down Notebook. Confirm the closing of the notebook by clicking OK on the confirmation dialog.
Running Notebook 3 of 4 - Re-writer
- Go to your 'Home' page in your Jupyter Notebook. This should be the previous tab in your browser.
- Navigate to the folder /home/llama-recipes/recipes/quickstart/NotebookLlama in the sidebar menu on the left.

- Change the second cell by adding the HuggingFace token for gated access of the Llama models:
import os os.environ["HF_TOKEN"] = "[your-hf-token]" MODEL = "meta-llama/Llama-3.1-8B-Instruct" - Run all cells inside the notebook
- Your final cell should look something like this

- Once your script is finished, close the notebook by clicking on File > Closed and Shut Down Notebook. Confirm the closing of the notebook by clicking OK on the confirmation dialogue.
Running Notebook 4 of 4 - Text-to-speech
- Go to your 'Home' page in your Jupyter Notebook. This should be the previous tab in your browser.
- Navigate to the folder /home/llama-recipes/recipes/quickstart/NotebookLlama in the sidebar menu on the left.

- Change the first cell by adding the ffmpeg, parler-tts and pydub installation
#!pip3 install optimum #!pip install -U flash-attn --no-build-isolation #!pip install transformers==4.43.3 !apt-get install -y ffmpeg !pip install git+https://github.com/huggingface/parler-tts.git !pip install pydub - Change the 17th cell by changing the device
device = "cuda" processor = AutoProcessor.from_pretrained("suno/bark") model = BarkModel.from_pretrained("suno/bark", torch_dtype=torch.float16).to(device)#.to_bettertransformer() - Change the 20th cell by changing the device
bark_processor = AutoProcessor.from_pretrained("suno/bark") bark_model = BarkModel.from_pretrained("suno/bark", torch_dtype=torch.float16).to("cuda") bark_sampling_rate = 24000 - Change the 24th cell by changing the device
parler_model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler-tts-mini-v1").to("cuda") parler_tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler-tts-mini-v1") - Change the 27th cell by changing the device
device="cuda" - Fix the 30th cell by adding the missing import
from scipy.io import wavfile from pydub import AudioSegment def numpy_to_audio_segment(audio_arr, sampling_rate): """Convert numpy array to AudioSegment""" # Ensure audio array is normalized to the range [-1, 1] audio_arr = np.clip(audio_arr, -1, 1) # Convert to 16-bit PCM audio_int16 = (audio_arr * 32767).astype(np.int16) # Create WAV file in memory byte_io = io.BytesIO() wavfile.write(byte_io, sampling_rate, audio_int16) byte_io.seek(0) # Convert to AudioSegment return AudioSegment.from_wav(byte_io) - Fix the 33rd cell by adding the missing import
import io final_audio = None for speaker, text in tqdm(ast.literal_eval(PODCAST_TEXT), desc="Generating podcast segments", unit="segment"): if speaker == "Speaker 1": audio_arr, rate = generate_speaker1_audio(text) else: # Speaker 2 audio_arr, rate = generate_speaker2_audio(text) # Convert to AudioSegment (pydub will handle sample rate conversion automatically) audio_segment = numpy_to_audio_segment(audio_arr, rate) # Add to final audio if final_audio is None: final_audio = audio_segment else: final_audio += audio_segment - Run all cells in the notebook
- By the end of this step, your final cell should resemble the example shown below:

- Once your script is finished, close the notebook by clicking on File > Closed and Shut Down Notebook. Confirm the closing of the notebook by clicking OK on the confirmation dialogue.
Play your AI-generated podcast
To play your generated podcast. Follow the instructions below:
- Go to your 'Home' page in your Jupyter Notebook. This should be the previous tab in your browser.
- Navigate to the folder /home/llama-recipes/recipes/quickstart/NotebookLlama/resources in the sidebar menu on the left.
- Right-click on the _podcast.mp3 file and click Download

- Go to your Downloads folder and double-click the file to play your AI-generated podcast
- Here's a demo of the audio podcast we generated. The image in the video has been added separately by us.
Troubleshooting Tips
If you are having any issues, please follow the following instructions:
Jupyter notebook server
To resolve any Jupyter Notebook Server issues, run the commands below to debug your errors.
ssh -i [path_to_ssh_key] [os_username]@[vm_ip_address]
# Once connected through SSH
# Check whether the cloud-init finished running
cat /var/log/cloud-init-output.log
# Expected output similar to:
# Cloud-init v. 24.2-0ubuntu1~22.04.1 finished at Thu, 31 Oct 2024 03:33:48 +0000. Datasource DataSourceOpenStackLocal [net,ver=2]. Up 52.62 seconds
# Check whether the Jupyter notebook server has started
docker ps
# Expected output similar to:
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 5c77b8a4154c jupyter_image "jupyter notebook --…" 1 second ago Up Less than a second 0.0.0.0:8888->8888/tcp, :::8888->8888/tcp inspiring_thompson
# Check any errors during Jupyter notebook server setup
# cat load_docker_error.log
Notebooks
In case you are running into any notebook issues or want to get started faster. Refer to our final notebooks here:
- Download Notebook 1 here
- Download the updated requirements.txt file here
- Download Notebook 2 here
- Download Notebook 3 here
- Download Notebook 4 here
Step 5: Hibernating Your VM
When you're finished with your current workload, you can hibernate your VM to avoid incurring unnecessary costs:
- In the Hyperstack dashboard, locate your Virtual machine.
- Look for a "Hibernate" option.
- Click to hibernate the VM, stopping billing for compute resources while preserving your setup.
To continue your work without repeating the setup process:
- Return to the Hyperstack dashboard and find your hibernated VM.
- Select the "Resume" or "Start" option.
- Wait a few moments for the VM to become active.
- Reconnect via SSH using the same credentials as before.
Explore our tutorial on Deploying and Using Stable Diffusion 3.5 and Llama 3.2 on Hyperstack.
FAQs
What is Notebook Llama?
Meta has just released NotebookLlama, an AI tool that automatically creates podcasts from PDF files. This tool is an open-source alternative to the Audio Overview feature in Google's Notebook LM.
How to set up Notebook Llama on Hyperstack?
The main steps to setting up Notebook Llama on Hyperstack include accessing Hyperstack, deploying a new virtual machine, setting up the model and running Jupyter Notebooks.
What GPU should I select for deploying Notebook Llama?
For using the smaller Llama 1B and 8B Llama models, we recommend choosing the NVIDIA RTX A6000 x1. For using the larger Llama 70B model we recommend the NVIDIA A100 x2.
Can I pause my virtual machine after using Notebook Llama on Hyperstack?
Yes, you can hibernate your VM to avoid unnecessary costs, preserving your setup for future use without incurring compute charges.
Subscribe to Hyperstack!
Enter your email to get updates to your inbox every week

